
After fifteen years of renting intelligence from the cloud, the most interesting AI machine of 2026 is sitting on your desk. NVIDIA and Microsoft's RTX Spark gives a personal computer a petaflop of AI compute and 128 GB of unified memory. That is enough to run a 120-billion-parameter model with a million tokens of context, locally, on hardware you own outright. The petaflop gets the headlines. The word "personal" coming back is what matters.
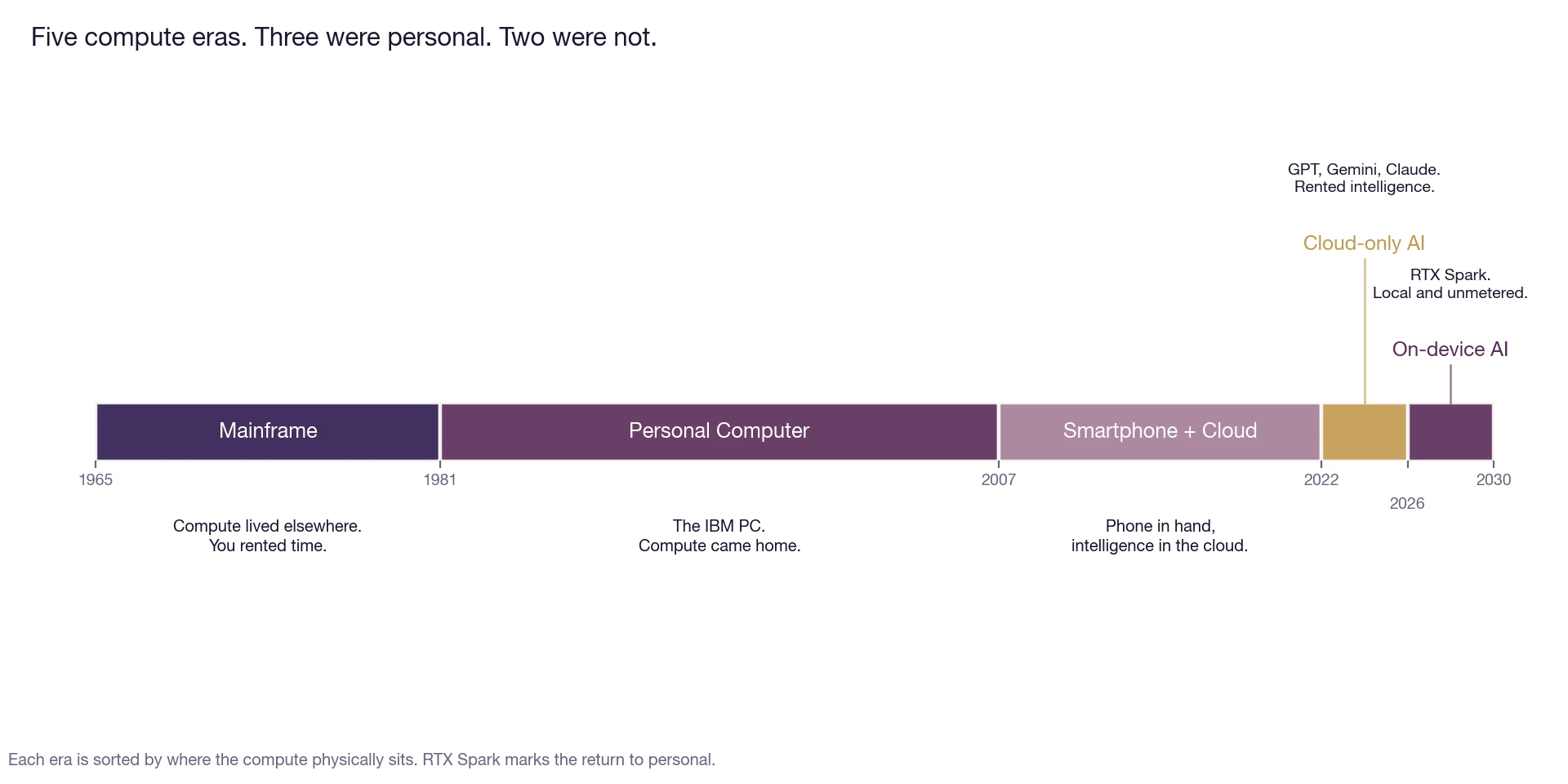 Fig. 1: Five compute eras, sorted by where the compute physically sits. Three of them were personal. Two of them were not. RTX Spark is the first machine that puts AI work back on the user's desk.
Fig. 1: Five compute eras, sorted by where the compute physically sits. Three of them were personal. Two of them were not. RTX Spark is the first machine that puts AI work back on the user's desk.
For fifteen years the smartest piece of software you used every day did not run on your computer. It ran in someone else's data center, behind a browser tab and a metered API. We started calling that arrangement "the cloud" and stopped noticing it was an arrangement at all. AI deepened the pattern. The frontier models of 2023, 2024 and 2025 were all rented, all metered, all phoning home. The PC turned into a thin client for a remote brain.
Spark changes the geometry. NVIDIA and Microsoft's new superchip is the first time a personal computer has been engineered around the assumption that AI runs on the device [1]. The headline specs are roughly a petaflop of AI compute and up to 128 gigabytes of unified memory, in a machine that fits on a desk and runs on a wall outlet. The headline numbers are not the point. The point is that "personal," the original animating idea of the IBM PC, has come back to computing for the first time in a generation, and AI is the reason.
What Spark actually is
The chip is a heterogeneous system-on-package: a high-end CPU, a tensor-rich GPU and a dedicated AI accelerator block that share one large pool of unified memory [2]. Two design decisions matter more than the rest.
The first is the unified memory. In a traditional PC the GPU has its own video memory and the CPU has system DRAM, and moving tensors between them is a real bottleneck. Spark removes the split. CPU, GPU and AI accelerator address the same physical memory, and a model's weights sit there once. No copy, no shuttle, no PCIe-bound penalty for crossing devices. Apple solved this for laptops with the M-series. Spark applies the same architectural decision to a Windows PC at much larger scale.
The second is FP4. The numeric format on which Spark runs its AI workloads is four-bit floating point, with a small extra byte of metadata per block of values to recover dynamic range [3]. FP4 is roughly half the memory of FP8 and a quarter of the FP16 most cloud inference still uses. Combined with the 128 GB pool, FP4 is what makes a 120-billion-parameter model fit on the machine at all. Without it you would be looking at 240 GB just for the weights, and the whole thing collapses.
A petaflop of compute is a lot of compute. It is not the binding constraint on what you can run locally. Memory is the binding constraint, and FP4 is the move that opens it.
What actually fits on the machine
Memory ceilings sound abstract until you draw them.
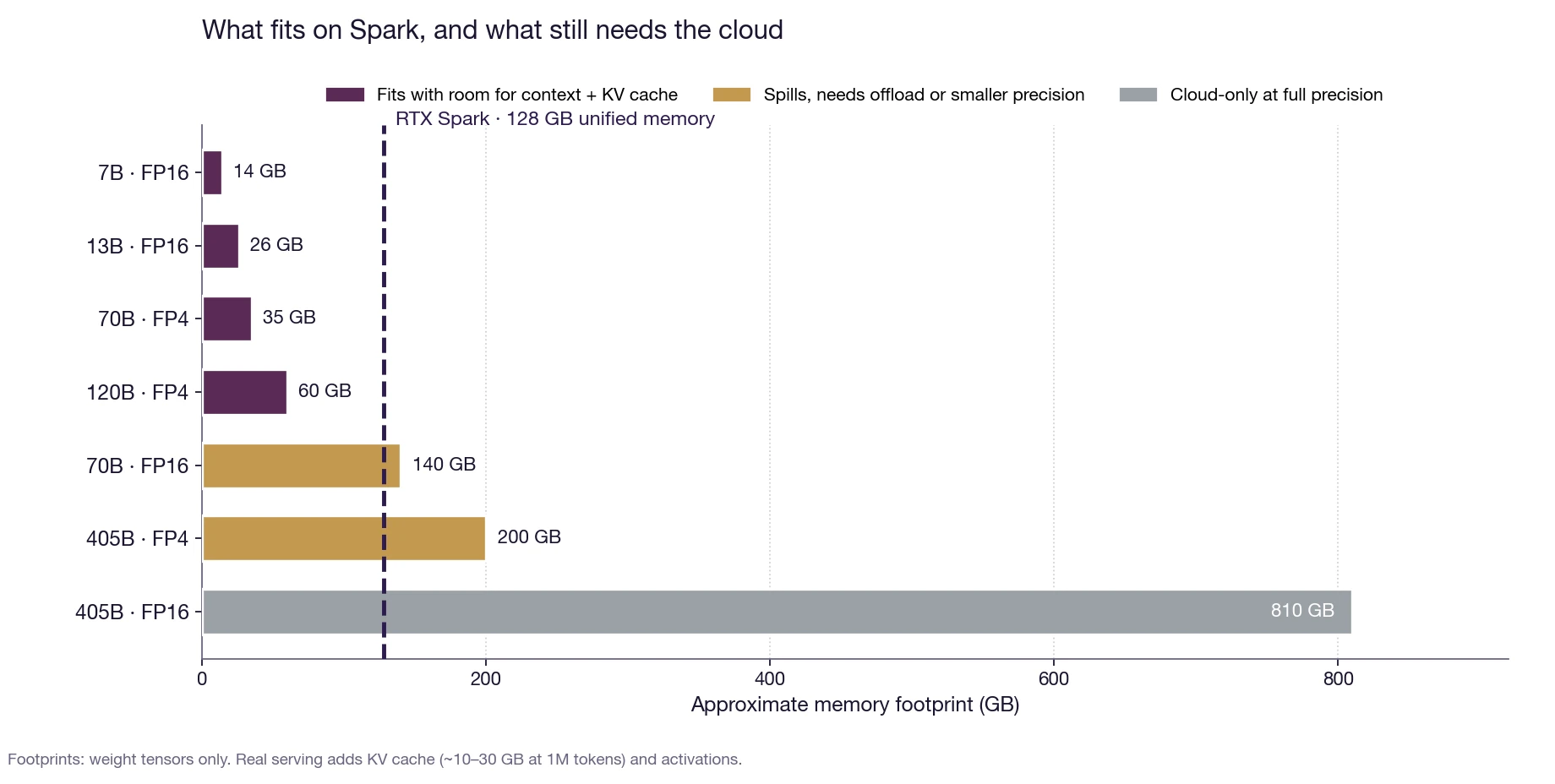 Fig. 2: Memory footprints for representative models. With 128 GB of unified memory and FP4 weights, a 120B model fits with room left over for context and the KV cache. A 405B model at full precision is still cloud-only.
Fig. 2: Memory footprints for representative models. With 128 GB of unified memory and FP4 weights, a 120B model fits with room left over for context and the KV cache. A 405B model at full precision is still cloud-only.
A 7B model in FP16 takes about 14 GB. A 70B model in FP16 needs roughly 140 GB and overflows the machine. The same 70B model quantized to FP4 fits in about 35 GB, which leaves more than half the unified memory for context, the KV cache and a second model running in parallel. A 120B FP4 model arrives at around 60 GB and still has working room. A 405B model in FP16 is still cloud-only at the better part of a terabyte; you cannot pretend otherwise. The largest frontier models have not moved on-device, and they will not in this generation. What did move on-device is the long fat middle of useful capability.
Spark is not a machine that runs the frontier locally. It is a machine that runs the eighty percent of useful AI work locally, with a long meeting's worth of context, without a per-token meter. That changes what a piece of software is allowed to assume about its environment.
The trust model matters more than the silicon
For two years now, the gating question on agentic AI has not been horsepower. It has been: would you let a piece of software open your files, click around your apps, send messages on your behalf, and pay for things from your account? The answer for most people, most of the time, has been no, and reasonably so. The data went to a cloud you did not control, the agent's reasoning was opaque, and your only audit trail was a chat log.
Spark, paired with Microsoft's on-device control layer, changes that question. The OS now exposes a permissioning model where an agent declares up front what it needs to touch (these files, these apps, this much spend) and the user grants or denies at that granularity [4]. Sensitive work stays in local memory. Anything that does need to leave for the cloud is filtered through a privacy boundary that scrubs personal identifiers before it goes. Because the model is running on your hardware, the audit trail is a local log file you own.
Satya Nadella's framing for this was "unmetered intelligence on every desk." The word "unmetered" carries a lot of weight. Cloud AI is metered three times: by token, by API call, and by privacy budget. Local AI is metered by electricity. Once tokens stop carrying a per-call price, asking an AI a question stops being an economic decision. You use it the way you use a search engine, or the way you tab to a calculator. That changes how often you use it, and what you use it for.
Cloud AI is metered three times: by token, by API call, and by privacy budget. Local AI is metered by electricity.
The economics of unmetered
The cost arithmetic of cloud inference is straightforward. At a million tokens of input and output, a current frontier model runs anywhere from a few cents to a few dollars depending on model and provider. That is cheap for a single query. It is not cheap for an agent that runs in a loop, calls itself, retries, fans out, and chews through tokens on your behalf for a week.
The arithmetic on Spark is different. Inference does not have a marginal price per token. It has a marginal price per kilowatt-hour. On a 200-watt machine running flat out, an hour of inference costs roughly the same as an hour of streaming high-definition video. The token throughput at that wattage is workload-dependent, but call it on the order of 50 to 150 tokens per second on a quantized 70B model. Run an agent for an hour and you have generated several hundred thousand tokens for the cost of running a desk lamp.
The workloads that change first are the ones that were too expensive to do well in the cloud: long-running personal agents, always-on summarization of your own data, real-time multimodal assistants that listen and watch all day. None of those clear the cost-per-outcome bar at cloud rates. All of them clear it at electricity rates.
The privacy and sovereignty argument
Cost is the popular story. Privacy is the bigger one for the industries that move next.
Healthcare, financial services, defense, legal: every one of these has spent the cloud era doing AI through a glass wall. The vendor offered a model. The customer was not allowed to send the patient record, the trade book, the case file, the classified document. So the customer either built a private deployment of an open-weight model on their own infrastructure (expensive, slow, perpetually behind the frontier) or did not use AI on their most valuable data at all.
A Spark-class machine inverts that posture. The data never leaves the device. The audit trail never leaves the device. The compliance officer is not asking "where is this data going" because the answer is on the desk. Hospitals, hedge funds and law firms are about to discover that the AI they were not allowed to deploy on their hardest problems is exactly the AI they can deploy now.
This is also where the open-weight ecosystem's last decade of work pays off. Llama, Mistral, Qwen, DeepSeek, IBM's Granite. The models that ship with permissive licenses and local-first deployment in mind are the ones that benefit. Frontier closed models did not invest in being good at running locally, because their business model is API tolls. Local deployment is where the open-weight players have a structural advantage, and Spark is the hardware they have been waiting for.
Cloud vs on-device, and why hybrid wins
It would be too neat to write that on-device wins everything. It does not.
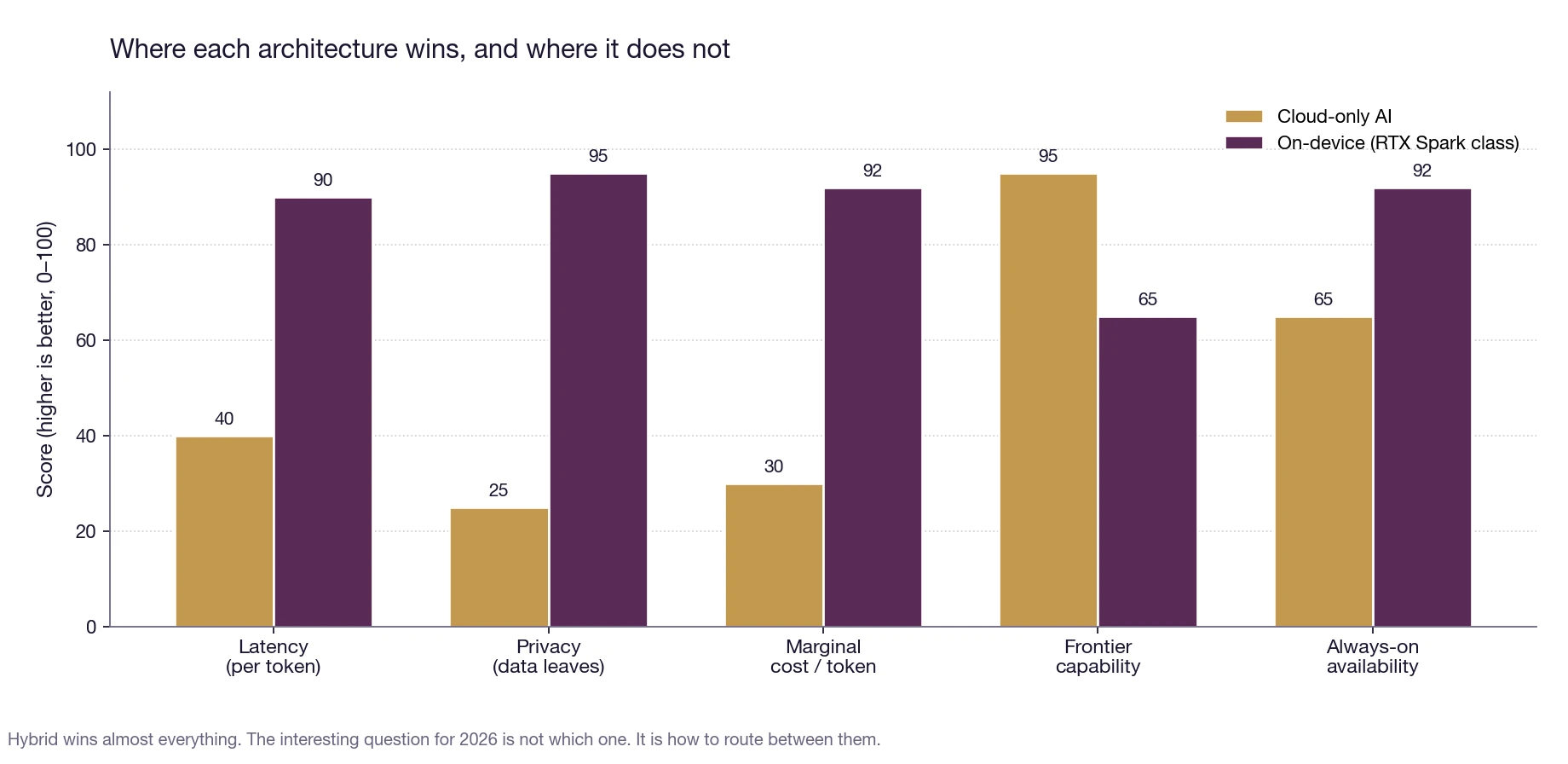 Fig. 3: Cloud-only versus on-device on five axes. Cloud keeps the frontier-capability ceiling and automatic multi-device sync. On-device wins on latency, privacy, marginal cost and offline availability. The interesting design question for 2026 is how to route between them, not which to pick.
Fig. 3: Cloud-only versus on-device on five axes. Cloud keeps the frontier-capability ceiling and automatic multi-device sync. On-device wins on latency, privacy, marginal cost and offline availability. The interesting design question for 2026 is how to route between them, not which to pick.
The cloud is still where the absolute frontier runs. A 405B-parameter model trained on ten trillion tokens has more raw capability than a 120B model. If your task needs the frontier (frontier scientific reasoning, frontier coding on a million-line codebase, frontier multimodal) the cloud is still the answer. Cloud is also still the answer for any workload that needs to be the same on your phone, your tablet and your laptop without you thinking about it.
What changes is everything in between. The right architecture for 2026 is hybrid: a small, fast, local model handles the eighty percent of requests that do not need the frontier, while a privacy-preserving routing layer escalates the hard twenty percent to the cloud. Latency goes down because most queries never leave the device. Cost goes down because most queries are metered in watts, not tokens. Privacy goes up because the sensitive eighty percent never leaves at all. The cloud bill shrinks because it stops paying for routine work.
Spark does not kill the cloud. It does not move the frontier on-device. What it enables is the right work running in the right place, which has not been the default since the smartphone era began.
What needs to be true for this to take hold
Hardware never wins on hardware alone. For the on-device shift to happen, three things have to come together over the next twelve months.
The OS has to make agentic permissioning a first-class concern. Right now, on-device agent permissions on Windows, macOS and Linux are a patchwork of shell scopes, sandbox profiles and per-app capability prompts. None of those scale to an agent that wants to touch fifteen apps and a hundred files in the course of a single task. The OS that gets this right (clear, granular, auditable, with a kill switch the user can hit instantly) wins the on-device era.
The developer story has to mature past the "drop-in replacement for OpenAI's API" pattern. On-device inference has different ergonomics: you load weights once and amortize, you batch differently, you actively manage the KV cache. SDKs like ONNX Runtime, llama.cpp, MLC and the new generation of Windows AI APIs are converging on this, but the experience for an application developer who just wants to ship is still ten years behind what the cloud SDKs offer.
The open-weight ecosystem has to keep delivering. A Spark-class machine is only as useful as the weights you can run on it. As long as Llama, Granite, Qwen, Mistral and DeepSeek keep releasing locally-deployable models that are a generation behind the frontier rather than three, the ceiling of useful local AI rises year over year. If license terms tighten, or if the best models go closed-only, the on-device shift slows.
None of these are speculative. All three are visibly in motion. None of them are guaranteed.
Three signals to watch
How will we know if Spark is the inflection point, or just an interesting peak? Three signals through the rest of 2026.
The first signal is regulated industries. When a hospital network publicly announces it is running clinical-decision-support AI on local Spark-class hardware in its own facilities, the privacy argument has won. This is the leading indicator I would look at hardest.
The second signal is the model mix. If the fraction of useful AI work running at the frontier versus one to two generations behind keeps tilting toward the not-frontier, the local-deployment argument is real. If frontier capability keeps gapping the rest, the local story stays interesting but does not take over.
The third signal is the OS layer. Whichever of Windows, macOS, ChromeOS or a Linux distribution ships the cleanest agentic permissions model, with a real kill switch and a real audit trail, decides where the on-device era is centered. Right now Microsoft is betting hard on Spark. Apple has not yet announced an equivalent.
What the return of "personal" means
The IBM PC was personal because the compute physically belonged to you. The smartphone was personal because the compute went where you went. The cloud era was many things, but it was not personal in either of those senses. Your most-used software ran somewhere you could not touch, and you paid rent for the privilege.
Spark is the first machine that lets the AI you depend on every day belong to you the way the spreadsheet on your hard drive belongs to you. It runs when your laptop runs. It does not phone home. The model and the agent and the data sit in the same physical place, on the same physical device, in the same hands. That is a different relationship to a piece of software than we have had in a long time.
Whether the machine that wins this era ends up being Spark, an Apple equivalent, or something neither company has announced yet, the architecture is now public. Personal compute is back.
References
[1] NVIDIA. "NVIDIA Announces DGX Spark and DGX Station Personal AI Computers," March 2025 (official press release renaming Project DIGITS). DGX Spark product page. Microsoft pairing announced at Build 2025: "The age of AI agents and building the open agentic web."
[2] NVIDIA. "NVIDIA Puts Grace Blackwell on Every Desk and at Every AI Developer's Fingertips," January 2025 (CES). Details the GB10 superchip and 128 GB coherent unified memory architecture addressable by CPU, GPU and AI accelerator without explicit copies. Apple's M-series silicon pioneered the unified-memory model for laptop-class AI workloads; Spark applies the pattern at PC-class scale.
[3] Rouhani et al. (joint AMD/Arm/Intel/Meta/Microsoft/NVIDIA/Qualcomm). "Microscaling Data Formats for Deep Learning," 2023. Defines MXFP4 (E2M1 mantissa with E8M0 shared scale) and underpins the Open Compute Project OCP Microscaling (MX) v1.0 spec. Block-scaled four-bit floating point recovers most of the dynamic range of FP8 at half the memory footprint, enabling 70B+ models to fit in 64–128 GB unified-memory machines.
[4] Microsoft. "Ignite 2025: Furthering Windows as the premier platform for developers, governed by security," November 2025. Covers per-agent IDs, least-privilege model, on-device registry, MCP proxy and the Settings → System → AI components → Agent tools control surface. User-facing companion: Microsoft Support: Experimental agentic features.
[5] See related context in Tokens Are Electricity on cloud-token economics, and The Real AI Cost Problem on the four-layer inference stack that compounds these gains.
Discussion
Sign in with GitHub to leave a comment or react. Threads are public and live in this site's GitHub Discussions.