The Real AI Cost Problem
Training a frontier model gets the headlines. Inference pays the bills.
Every ChatGPT conversation, every Claude call, every agent invocation runs the model through billions of calculations, and those calculations cost real money. According to analyst estimates, more than half of OpenAI's and Anthropic's revenue is spent on inference alone, before training costs are counted [1]. Long-range analyst projections put OpenAI's compute spend in 2028 around $121 billion and Anthropic's at roughly $30 billion [2]; those are scenario estimates, not audited numbers, but the shape of the curve is what matters. A training run is a one-time cost per model, and when it's over it's over. Inference keeps running as long as anyone's using the product. And with agents increasingly making multiple model calls per user task, the cost curve isn't flattening. It's bending the other way.
So the interesting question isn't whether inference needs to get cheaper. It obviously does. The interesting question is where the cheaper inference is going to come from.
You'll hear two common answers. One is that it's a chip problem: newer GPUs, more memory, bigger data centers. The other is that it's a software problem: smarter compilers, better serving systems. In practice, most of the gains come from how these layers interact, not from optimizing any one of them in isolation. Inference is a full-stack problem, and the real gains happen when four separate layers (the algorithm, the compiler, the runtime, and the silicon) are designed to work with each other instead of past each other.
What follows is a walk down that stack, one layer at a time. I've picked one or two recent examples per layer from work at Google, DeepSeek, NVIDIA, AMD, and my own group at IBM Research. These are illustrations, not a survey. The goal isn't to catalog every technique; it's to show how the layers interact.
Layer 1 — Algorithm: Shrink What You Carry, Skip What You Don't Need
The top of the stack is the model itself, and the data it drags around while it's working. Make that data smaller, or arrange things so the model touches less of it, and every layer underneath has an easier job. These are algorithmic moves, and in the best case they slot in without retraining or hardware changes. In the less-best case (which is what you run into in practice), they interact with the rest of the system in ways you have to design around.
Two angles matter here, and they're orthogonal. Compression is about how much data you hold. Sparsity is about how much of it you actually look at. Both have been active research areas for years; both have produced notable results in the last twelve months.
Compression: TurboQuant
The biggest piece of data most language models carry around is something called the KV cache: a kind of working memory that holds everything the model has already read in a conversation. Summarize a 500-page document and the KV cache is where the memory of those pages lives while the summary gets written. A million-token context, roughly 750,000 words, can fill hundreds of gigabytes of GPU memory with nothing but KV cache. One long query can tie up a whole server.
This is what makes the KV cache the dominant memory-bandwidth bottleneck during decoding. Each generated token has to read the entire cache from HBM (high-bandwidth memory) on the GPU. Even with a fast chip, you end up waiting on memory rather than doing arithmetic. Shrinking the cache doesn't just save capacity; it cuts the bytes you have to move on every token.
There's been a long line of research on this: KIVI, SmoothQuant, AWQ, and many others each take another chunk out of the memory bill. A recent entry worth singling out is TurboQuant, from Google Research, being presented at ICLR this month [3]. It quantizes the KV cache to roughly three bits per value (about six times smaller than a standard FP16 cache), with minimal accuracy impact on the benchmarks in the paper, and it doesn't require a fine-tuning or calibration pass. The underlying idea is a rotation into a different coordinate system where the values concentrate around zero and can be stored in far fewer bits.
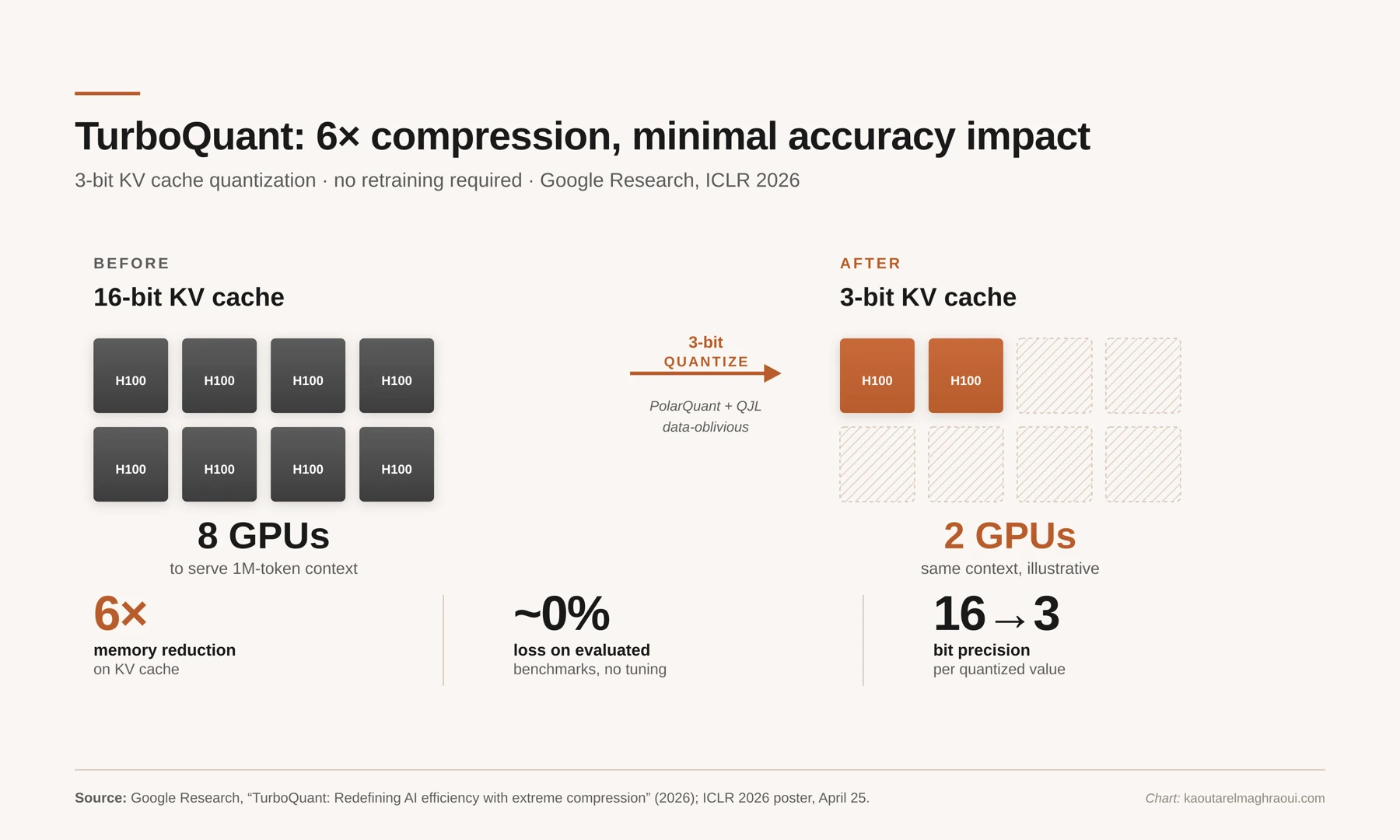 TurboQuant compresses the KV cache ~6× with minimal accuracy impact on evaluated benchmarks. The figure illustrates a 4–6× reduction on a hypothetical 1M-token workload; the real number depends on batch size, context length, and attention kernel implementation.
TurboQuant compresses the KV cache ~6× with minimal accuracy impact on evaluated benchmarks. The figure illustrates a 4–6× reduction on a hypothetical 1M-token workload; the real number depends on batch size, context length, and attention kernel implementation.
The practical implications are large, though the exact numbers depend on workload. For long-context, memory-bound inference, a compression factor of this size can reduce GPU requirements by a large multiple.
What I find most interesting about TurboQuant is how quiet the deployment is supposed to be. No retraining, no fine-tuning, no calibration pass. That's the ideal. In practice, aggressive KV quantization tends to interact with the rest of the stack in awkward ways: custom attention kernels assume specific memory layouts, and a new packing format can force a kernel rewrite; accuracy can degrade on out-of-distribution inputs the benchmark didn't cover; at extreme bit widths, quantization noise compounds over long generations; and de-quantization on the hot path can eat a surprising fraction of the gain if the kernel wasn't written carefully (you saved the HBM traffic, but now you're paying for the unpack every time you touch a cache entry). None of this is fatal, but it's the reason you don't see 3-bit caches deployed by default everywhere yet. The optimizations that win in practice are the ones whose system-level costs are low, not just the ones whose accuracy numbers look good in isolation.
The other thing worth flagging here, before we move on, is that a 6× reduction in KV memory ripples down the stack. Smaller caches mean larger achievable batch sizes, which is what lets the compiler and runtime layers actually pay off. I'll come back to this when we reach the compounding section, but the pattern starts at Layer 1.
Sparsity: Native Sparse Attention
Compression makes the data smaller. Sparsity asks a different question: do we even need to look at all of it?
When a model generates its next word, it attends back over everything it's already seen. But most of that earlier content doesn't matter to what comes next. The trouble is, the model doesn't know which parts matter until it looks. If there were a shortcut that let it skip the irrelevant parts of its own memory, you'd save a lot of work.
Sparse attention is a well-worn research area: heuristic pruning, structured block patterns, learned retrieval-style lookups, cross-layer index reuse [4] [5] [6]. The recent example that matters most, to me, is Native Sparse Attention (NSA), introduced by DeepSeek in early 2025 and reported to be deployed in their V3.2-Exp model release [7]. Rather than attend to every token, NSA runs three cheap sparse views of the context in parallel and learns how to combine them: a compression branch that summarizes groups of tokens into coarse blocks, a selection branch that picks the handful of tokens that matter most by a learned score, and a sliding window that keeps the recent tokens around so local context stays sharp.
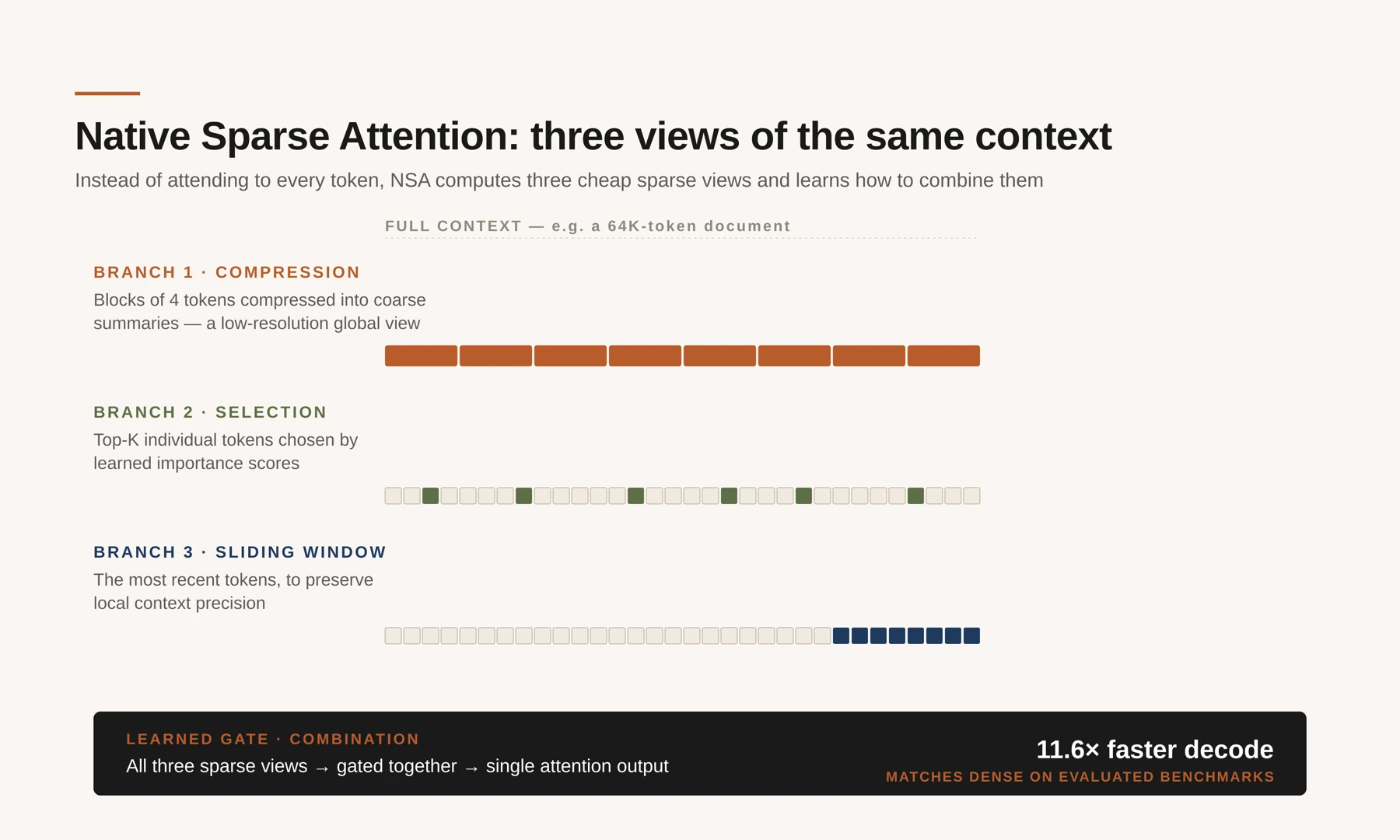 NSA computes three sparse views of the same context and learns to combine them: compression, selection, and sliding window. The three branches run in parallel and are fused by a learned gate.
NSA computes three sparse views of the same context and learns to combine them: compression, selection, and sliding window. The three branches run in parallel and are fused by a learned gate.
Two things about NSA are worth pausing on. First, it's hardware-aligned: it runs on stock GPUs via custom Triton kernels, no exotic memory required. Second, it's trained end-to-end from scratch rather than bolted on afterward, which means the model learns to take advantage of the sparsity instead of merely tolerating it. At 64K-token context, the paper reports up to 11.6× speedup in decoding over full attention, with accuracy matching or exceeding dense-attention baselines on long-context benchmarks [7].
Worth noting: sparse attention isn't a free lunch either. Sparsity at inference time introduces irregular memory access and data-dependent control flow. GPUs dislike both. Kernel performance depends heavily on how well the sparsity pattern maps to the underlying hardware's block structure, and aggressive sparsity can hit accuracy cliffs when the learned selection misses a globally important token. The gap between "sparse in theory" and "faster in production" has swallowed many promising techniques. NSA works partly because it's designed with the kernel in mind from day one.
My own group has been pushing this thread in a different direction. Our paper STARC, at ASPLOS this spring, is work out of the IBM–RPI Future of Computing Research Collaboration (FCRC), a joint effort between IBM Research and Rensselaer that I co-lead [8]. The question STARC asks is: if the memory system itself becomes programmable, what does sparse attention look like then? The target is Processing-in-Memory (PIM) hardware, still mostly research-stage but a plausible bet on where inference silicon is heading. By co-locating semantically related tokens in the same memory banks, STARC lets the hardware skip whole regions of the cache rather than streaming through them and filtering later. On PIM, that's a 93% cut in attention latency on the workloads we evaluated. The number is encouraging; the more interesting part is the question it opens up. If sparsity stops being a GPU kernel optimization and starts being a property of the memory architecture, the algorithm layer looks quite different from what it looks like today.
Step back from the specific techniques and notice the shape. Compression pays for the memory you hold; sparsity pays for the memory you touch. They attack different lines on the same bill, so you can apply them together and the gains combine rather than cancel. That's the whole idea of this layer: two complementary tools for getting more out of the same model without changing the model.
Layer 2 — Compiler: Turn the Model Into the Fastest Code You Can
Between the model a researcher writes in PyTorch and the instructions a GPU actually executes sits the compiler. Its job is translation. A high-level model graph, a sequence of mathematical operations in Python, has to be turned into a much larger body of hardware-specialized code, with operations fused where possible, memory layouts tuned to the silicon, and precision formats matched to what the hardware supports.
For most of the last decade, this translation was a human activity. Expert engineers wrote custom CUDA kernels for every operator, every hardware target, every precision format. A new chip meant rewriting everything. A new precision format (when FP8 landed on Hopper, when FP4 landed on Blackwell) meant another round. When people say "hand-tuned kernels," that's literally what they mean: humans writing assembly-adjacent C++/CUDA for specific machines, for months at a time.
Two things are changing fast. The compiler layer itself is crowded: TensorRT, XLA, Triton, MLIR/IREE, TVM, and others. The two recent results I find most illustrative of where the layer is going are torch.compile and DeepGEMM.
The first is about compilation going mainstream. PyTorch's built-in JIT compiler, torch.compile, spent a few years as a research feature and then turned into core infrastructure. In August 2025, vLLM (the dominant open-source serving framework for LLMs) adopted torch.compile as a central part of its inference pipeline, not an optional flag [9]. Reported speedups on LLM inference are typically in the 1.5–2× range with minimal model code changes, though your mileage varies by model and hardware. The work that used to be a weeks-long kernel-optimization project for every new model-and-GPU combination is becoming a runtime feature that ships with PyTorch.
In practice, torch.compile has its own rough edges. Graph breaks (places where the compiler falls back to eager execution) can silently erase most of the gain; dynamic shapes still surprise the tracer; and the first compilation can take minutes, which matters for autoscaling. None of these are fundamental, but they're the reason production teams still benchmark carefully rather than trust a 2× claim.
The second result is more striking. In February 2025, DeepSeek open-sourced DeepGEMM, an FP8 matrix-multiplication library targeting NVIDIA Hopper [10]. It hits 1350+ FP8 TFLOPS on H100, which is already very fast. What makes it notable isn't the raw throughput. It's that the whole thing is about 300 lines of CUDA, compiled just-in-time, and matches or beats NVIDIA's own expertly-tuned CUTLASS kernels across the matrix shapes LLMs actually care about. The gap between "a small team of specialists spending months on kernels" and "code generated automatically" has been closing for a while. DeepGEMM is the clearest sign I've seen that it's nearly closed.
Put those two stories together and you get the broader shape. Kernel-level optimization is going both mass-market and near-expert: torch.compile makes it a one-line change for anyone working in PyTorch, and libraries like DeepGEMM show that compiler-generated code can match what humans produce with effort. Every new GPU, every new precision format, every new model architecture now lands with near-optimal code much faster than before, instead of leaving a year of performance on the table while the hand-tuners catch up. That compresses the whole hardware-to-production cycle in a way that matters for inference economics as much as any silicon launch.
Layer 3 — Runtime: Schedule the Same Silicon Better
The next layer is the software that orchestrates live inference workloads, what engineers call the "runtime." Where the compiler decides how each operator runs on a GPU, the runtime decides when requests run, how they get batched, how the KV cache is managed as responses stream out, and how work gets distributed across GPUs.
Activity at this layer has been relentless: vLLM, TGI, TensorRT-LLM, SGLang, Dynamo, and others. The best recent snapshot of just how fast things are moving comes from MLPerf, the industry's standard inference benchmark, which runs every six months. The results that dropped in April were striking. On DeepSeek-R1, a popular reasoning model, NVIDIA's top GPUs were 2.77× faster than they had been six months earlier, on the same physical hardware [11] [12]. 8,064 tokens per second per GPU, up from 2,907. Nothing changed except the software.
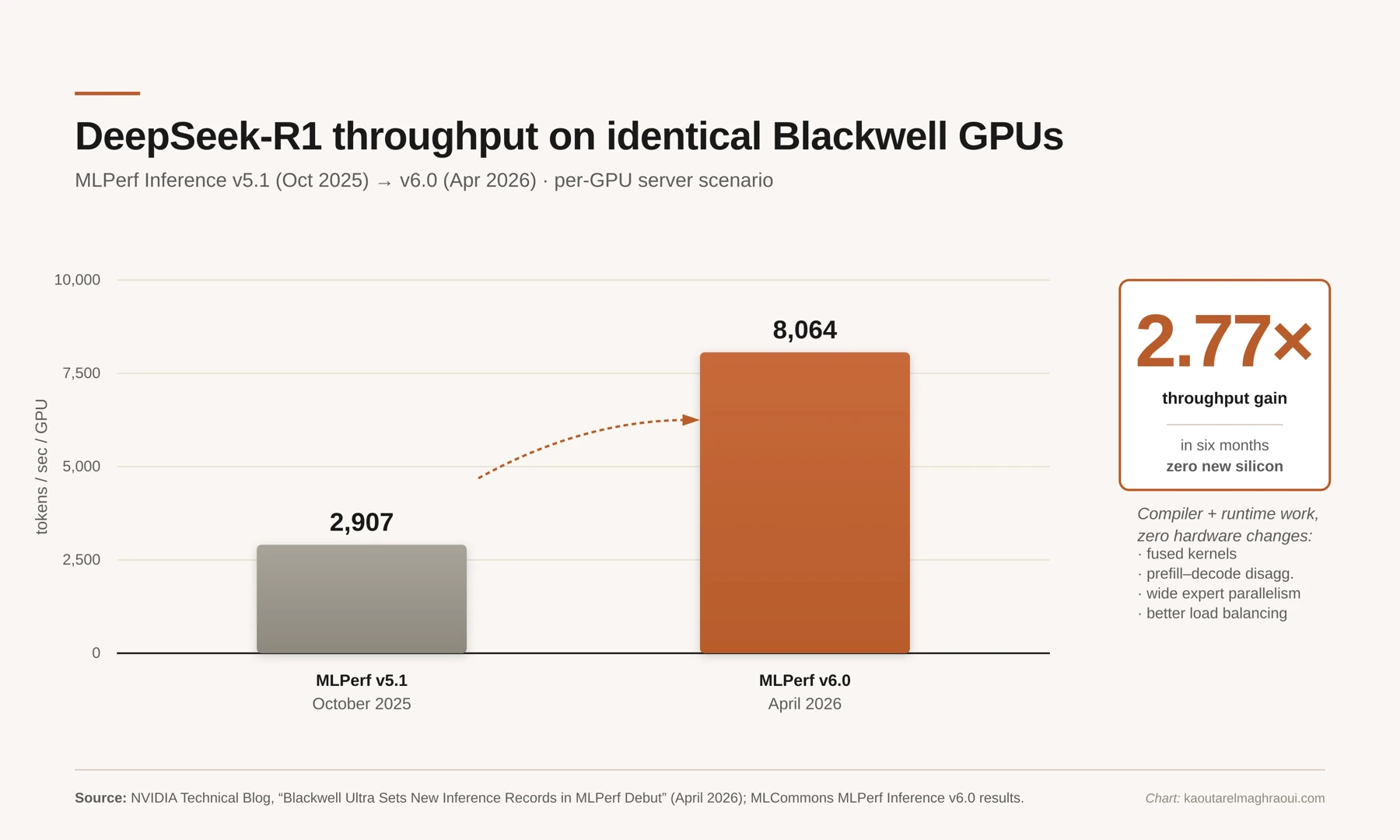 MLPerf Inference v5.1 (Oct 2025) vs. v6.0 (Apr 2026) on identical GB300 hardware. The gain came entirely from TensorRT-LLM and runtime-level improvements, not new silicon.
MLPerf Inference v5.1 (Oct 2025) vs. v6.0 (Apr 2026) on identical GB300 hardware. The gain came entirely from TensorRT-LLM and runtime-level improvements, not new silicon.
That 2.77× is a combined result from work at two layers. Some of it is compiler-level: better kernel fusion, tighter memory layouts, sharper operator scheduling. The rest is genuinely runtime-level: wide expert parallelism for Mixture-of-Experts models, prefill-decode disaggregation, multi-token prediction, KV-aware routing, and a long tail of other scheduling tricks. Neither layer would have gotten there alone. They had to push on the same silicon at the same time, and the dormant performance was there to be found.
The runtime layer has its own constraints that limit how far it can go. Batching is the main tool for raising utilization, but bigger batches increase latency for individual requests, and production systems usually have strict tail-latency targets. Prefill-decode disaggregation helps, but only when your traffic has the right mix. KV-aware routing is powerful but introduces hot spots when popular prefixes draw disproportionate traffic. The 2.77× gain came from tightening all of these simultaneously, not from any single intervention.
This is an old pattern in computing: the chip that ships is rarely as fast as the same chip will be a year later, because the software catches up to it. What's different this time is the rate of catch-up. A 2.77× gain in six months is extraordinary by any historical standard, and it's a strong hint that the software side of this stack still has room to go.
Layer 4 — Hardware: When the Chip Mirrors the Software
At the bottom of the stack is the silicon. This is the layer that gets the news coverage, new chips, new racks, new data centers, and it matters, but not always for the reasons most people assume.
Start with the competitive picture. MLPerf v6.0 made clear that the GPU market is no longer a one-vendor story. AMD's Instinct MI355X cleared a million tokens per second on Llama 2 70B at cluster scale and came within about 16% of NVIDIA's B200 at single-node on the same benchmark. On the interactive scenario, it outperformed B200 on this workload, delivering 119% of B200's performance [13]. Twenty-four organizations submitted this round [11]. That matters for inference economics in a fairly direct way: more competition, downward pressure on prices, and different architectures optimized for different workloads.
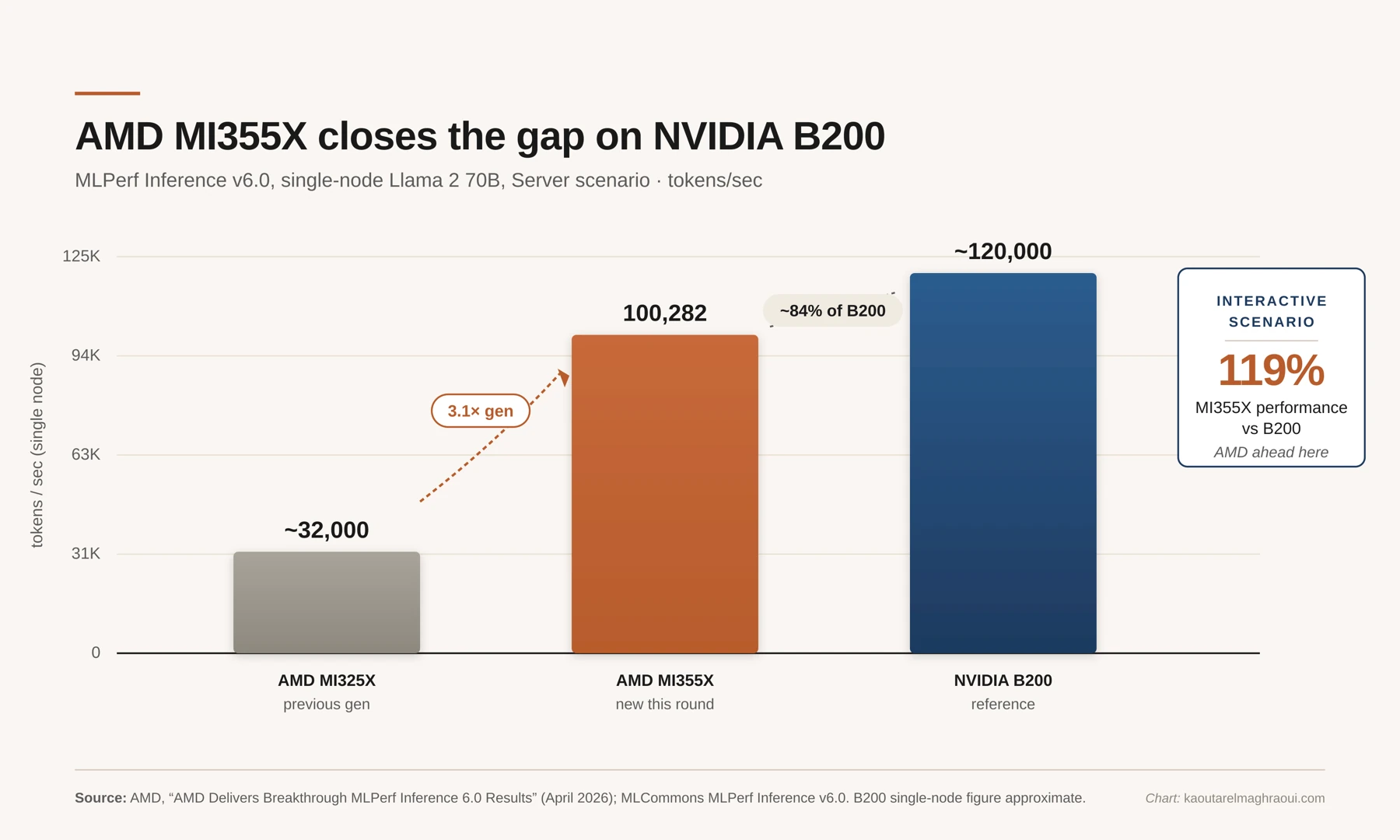 MLPerf v6.0 single-node comparison on Llama 2 70B. The MI355X comes within ~16% of B200 on offline throughput and beats it on the interactive scenario.
MLPerf v6.0 single-node comparison on Llama 2 70B. The MI355X comes within ~16% of B200 on offline throughput and beats it on the interactive scenario.
There's a lot of activity in inference-specific silicon right now beyond NVIDIA: AMD, Intel Gaudi, Google TPU, AWS Trainium and Inferentia, Cerebras, Groq, IBM's own AIU work. But the design move I find most illustrative is the one NVIDIA has been calling disaggregation. Traditionally a single GPU handles the whole inference path, reading the prompt and then generating the response, on one chip. Those two phases have fundamentally different characteristics. Prefill is compute-bound: you're processing a lot of tokens in parallel, so the chip's arithmetic units are the bottleneck. Decode is memory-bandwidth-bound: you generate one token at a time, but each token has to read the entire KV cache from HBM. Forcing one chip to be excellent at both is a compromise, and everyone has always known it.
The roofline model makes this concrete. Decode on long contexts sits far on the memory-bandwidth side of the roofline: the chip's arithmetic units are mostly idle because they're waiting for bytes to arrive from HBM. No amount of extra FLOPs helps when the bandwidth ceiling is what's binding. This is also why architectural choices like dataflow vs. control-flow execution matter for inference: dataflow designs (TPU-style, IBM AIU, Cerebras) can keep data moving through a fixed pipeline without control-flow overhead, which suits decode's regular access patterns well. Control-flow designs (stock GPUs) have more flexibility for heterogeneous workloads but pay more per-token overhead on memory-bound inner loops. Disaggregation is the industry's way of saying: stop trying to split the difference on one chip, and let each half of the workload run on silicon that matches its actual bottleneck.
NVIDIA's answer, starting with Rubin CPX unveiled in September 2025, is to stop compromising and split the work between two different kinds of chips, each optimized for its half of the job [14]. The full Rubin platform, announced at CES in January, pushes that logic harder: six different custom chips, designed as a coherent system [15].
The most interesting thing about Rubin isn't the chips themselves. It's that prefill-decode disaggregation was already being implemented at the runtime layer (Layer 3, a page ago). The hardware is now catching up to a structure that the software had already discovered on last-generation silicon. Software finds a pattern, hardware re-architects to match. That sequence, more than any specific chip, is what convinces me the co-design view of AI has won the argument.
How the Four Layers Compound
Each layer on its own is valuable. The point of telling the story layer by layer is that they multiply, not add.
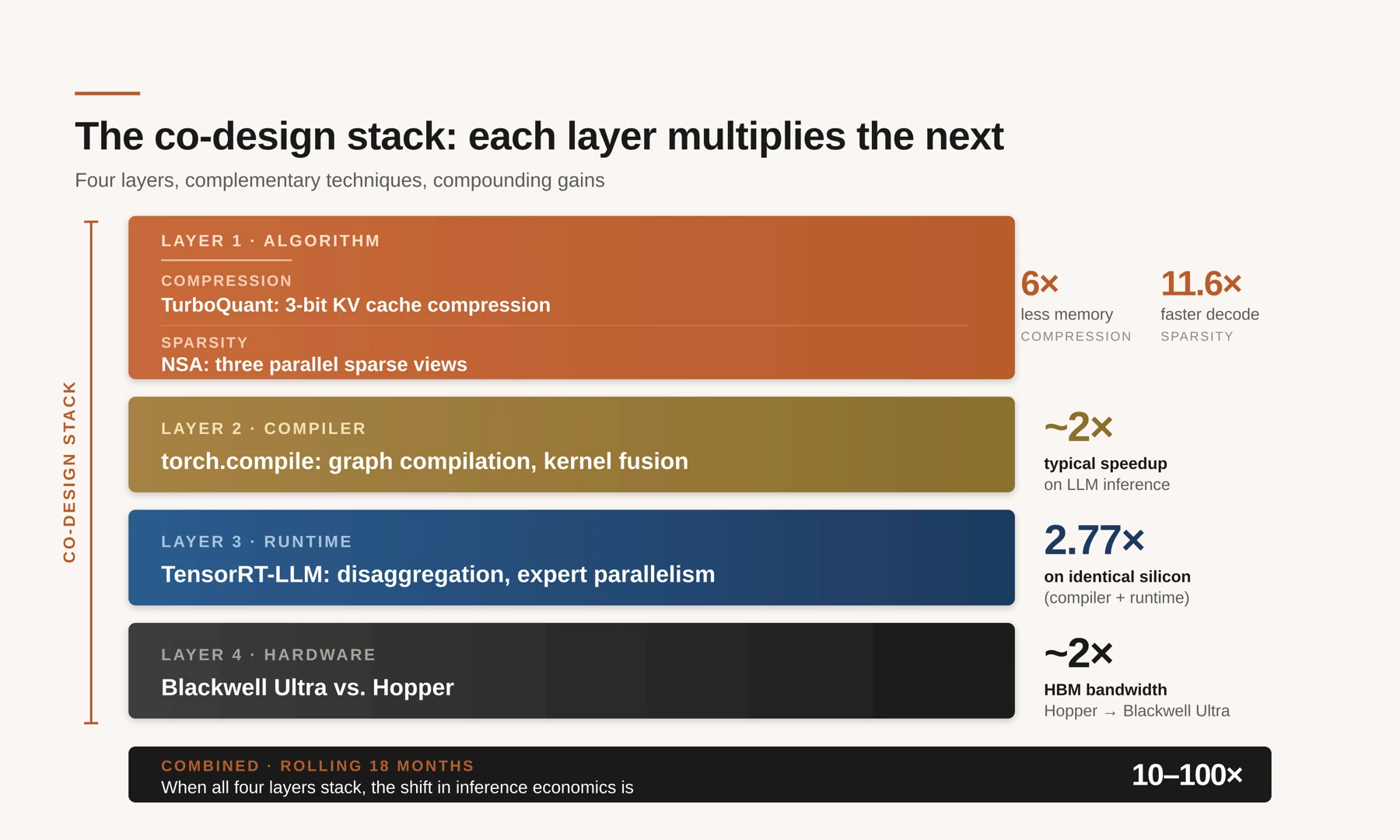 Four layers, complementary techniques at each, compounding to the 10–100× gains the industry has seen in the last eighteen months.
Four layers, complementary techniques at each, compounding to the 10–100× gains the industry has seen in the last eighteen months.
The compounding is actually straightforward once you trace it through. KV compression reduces memory bandwidth pressure → enables larger batch sizes → improves GPU arithmetic utilization → amplifies the payoff from runtime scheduling and kernel fusion → which in turn shifts the bottleneck back toward memory, opening new room for sparsity. Each improvement at one layer changes what's worth doing at the next.
Walk through it concretely. A 6× reduction in KV cache memory at the algorithm layer doesn't just save capacity. It directly raises the batch size a given GPU can serve, because KV memory is the binding constraint for long-context inference. Bigger batches are what lets compiler-level work pay off: fused kernels only amortize their overhead when there's enough parallel work to keep the arithmetic units busy. Higher arithmetic utilization, in turn, shifts the bottleneck back toward memory, which is where sparsity now has something to contribute (touching less of the cache on each token). And the new silicon at the bottom, especially disaggregated designs that put prefill and decode on separate chips matched to their actual bottlenecks, makes the whole thing run faster still.
That's why the industry has seen 10–100× improvements in inference economics over the last eighteen months. Not because any single team had a breakthrough, but because four groups that historically didn't talk to each other have been forced to coordinate. The best production AI teams I know are organized around the whole stack, not around any single slice. A hardware team that doesn't know how the attention kernels are fused will leave bandwidth on the table; a compiler team that doesn't understand the memory-access pattern will fuse operators that should have stayed separate; an algorithms team that doesn't know how the runtime batches requests will design techniques that look great in the paper and fall apart in production.
What This Means If You're Building a System Today
If you're operating or building inference infrastructure right now, the order in which to apply these ideas matters more than any single technique. Here's roughly how I'd sequence it:
- Start with the algorithm layer, especially KV cache compression. It's the highest-leverage intervention that doesn't require coordinated changes elsewhere, and for long-context workloads it often removes the memory bottleneck that was limiting everything else.
- Then look at the compiler and runtime layers together. Once the memory pressure is reduced, batching becomes more productive and kernel fusion starts to pay off.
torch.compileplus a modern serving stack (vLLM, TensorRT-LLM, SGLang) is the usual path. - Add sparsity selectively. Sparse attention gives the biggest wins at very long contexts, but it has accuracy and kernel-compatibility risks, so it belongs later in the sequence rather than earlier.
- Only scale hardware after the software stack is tight. Running out to buy more GPUs before you've squeezed the current fleet is a common and expensive mistake. The 2.77× MLPerf result is a pointed reminder of how much performance is typically sitting dormant.
None of this is a recipe. Every deployment has its own mix of traffic patterns, latency targets, and hardware constraints. But the sequence reflects how the layers depend on each other.
Where the Next 10× Comes From
This whole post has been building toward one diagram. Figure 5 shows four layers compounding over a rolling eighteen-month window. It's a satisfying picture, and it's the picture most of our current optimization work has been reaching toward.
Here's the harder question, the one I keep circling back to: if the four-layer stack has already compounded to 10× or 100×, where does the next 10× come from?
I'm not sure it comes from any of these four layers. The algorithm layer is approaching a more fundamental transition: we've been treating this as a lossy-compression problem, but the next phase is probably semantic filtering. The model doesn't just need to store bits more efficiently; it needs to choose what to forget. That's a different kind of optimization, and it points toward architectures built around selective retention rather than compressed retention. The compiler layer is closing the gap with expert hand-tuning, and the closer the catch-up gets, the less room is left. The runtime layer is running out of scheduling slack. The hardware layer will keep iterating, but the pace of manufacturing-process improvements is slowing.
The next 10× probably comes from somewhere the current diagram doesn't yet have a row for. Training-inference co-design, where the model is designed from day one with its deployment stack in mind rather than adapted to it after the fact. Architectures that are natively sparse rather than retrofitted to be. Memory technologies that change what's physically possible: CXL-attached pools, next-generation HBM, processing-in-memory. Non-von-Neumann substrates for specific workloads: Ising machines and other combinatorial-optimization hardware for the planning and search components of reasoning pipelines, analog in-memory compute for certain attention patterns. Or agentic workloads, which invoke a model many times per task and don't fit the request-response paradigm the whole stack is currently built around.
I don't know which of those will matter most. What I'm fairly sure of is that the people who figure it out first will be the ones who understand every layer of the current stack well enough to see where it's about to crack. That's the research agenda I'm investing in at IBM Research, and it's the kind of thinking I try to build in the graduate students I teach at Columbia.
For readers curious about the business context behind all of this, why inference economics is the defining question for AI companies right now, and how OpenAI's and Anthropic's very different cost structures are likely to play out, I wrote about that in more depth last week.
The four-layer stack won't be the last one we draw. If the last eighteen months are any guide, somebody will be adding a fifth row to this diagram a year from now, and the compounding will start over.
Related Reading
The AI Inflection Point: Economics, Discovery, Cybersecurity — April 13, 2026 The previous post in this series, covering OpenAI and Anthropic's diverging cost structures, AI's accelerating role in scientific discovery, and the shifting cybersecurity picture.
References
[1] Wall Street Journal, "OpenAI and Anthropic IPO Finances," April 6, 2026. Analyst estimates; not audited financial breakdowns.
[2] SaaStr, "Anthropic Just Passed OpenAI in Revenue While Spending 4x Less to Train Their Models," April 2026. Long-range compute spend figures are analyst projections under scaling assumptions, not company guidance.
[3] Zandieh, Daliri, Hadian, Mirrokni, "TurboQuant: Online Vector Quantization with Near-Optimal Distortion," arXiv:2504.19874; ICLR 2026, April 25, 2026. Google Research blog, "TurboQuant: Redefining AI efficiency with extreme compression," March 24, 2026.
[4] Acharya et al., "Star Attention: Efficient LLM Inference over Long Sequences," NVIDIA, ICLR 2025.
[5] Gao et al., "SeerAttention: Learning Intrinsic Sparse Attention in Your LLMs," Microsoft Research, ICLR 2025.
[6] Deshmukh, Goyal, Kwatra, Ramjee, "Kascade: A Practical Sparse Attention Method for Long-Context LLM Inference," arXiv:2512.16391, December 18, 2025.
[7] Yuan et al., "Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention," DeepSeek-AI, arXiv:2502.11089, February 16, 2025. Reported deployment in DeepSeek-V3.2-Exp, September 29, 2025.
[8] Fan et al., "STARC: Selective Token Access with Remapping and Clustering for Efficient LLM Decoding on PIM," IBM Research and Rensselaer Polytechnic Institute (IBM–RPI Future of Computing Research Collaboration), ASPLOS 2026.
[9] vLLM Blog, "Introduction to torch.compile and How It Works with vLLM," August 20, 2025.
[10] DeepSeek-AI, "DeepGEMM: clean and efficient FP8 GEMM kernels with fine-grained scaling," February 2025.
[11] MLCommons, "MLPerf Inference v6.0 Benchmark Results," April 1, 2026.
[12] NVIDIA Technical Blog, "NVIDIA Extreme Co-Design Delivers New MLPerf Inference Records," April 2026.
[13] AMD, "AMD Delivers Breakthrough MLPerf Inference 6.0 Results," April 2026.
[14] NVIDIA Newsroom, "NVIDIA Unveils Rubin CPX: A New Class of GPU Designed for Massive-Context Inference," September 9, 2025.
[15] NVIDIA Newsroom, "NVIDIA Kicks Off the Next Generation of AI With Rubin: Six New Chips, One Incredible AI Supercomputer," January 5, 2026.
Discussion
Sign in with GitHub to leave a comment or react. Threads are public and live in this site's GitHub Discussions.