Insights on AI research, hardware innovation, leadership, and the future of computing.
Every time a new AI chip arrives, someone has to get your model running on it, and that takes days to weeks. DeepView, our open-source tool from IEEE SSE 2026, finds the three failures that block it and cuts diagnosis to minutes.
I opened IBM Technology in Action DACH with a keynote on generative systems. My argument: the future of computing is not one bigger model but a co-designed system of efficient small models, typed programming, open agent standards, and custom silicon like Spyre.
Weight quantization solved the model-size problem. But at 128K context, the KV cache dwarfs the model itself. A tutorial and survey of the 2026 techniques that compress it 20-40x.
IBM turns 115 this year. Its real genius was never predicting the future. It was the discipline to tear down its own winners and rebuild — from punch cards to the System/360 to the quantum and enterprise-AI bets it is making now. A systems researcher's celebration.
Morocco is building one of Africa's most ambitious AI foundations. The real question is no longer whether we can build data centers. It is whether we can build the software, models, and talent pipelines to make them sovereign.
Models remain important, but the strategic control point in AI systems is increasingly the routing layer that determines which model, hardware, policy, safety constraint, and cost profile applies to each request.
After fifteen years of renting intelligence from the cloud, the most interesting AI machine of 2026 is sitting on your desk. NVIDIA and Microsoft's RTX Spark gives a personal computer a petaflop of AI compute and 128 GB of unified memory, enough to run a 120B model with a million tokens of context, locally, on hardware you own. A hardware-and-systems read on what actually changes.
Uber blew its annual AI budget by April. Amazon shut down its internal AI leaderboard after employees gamed it. MIT found that 95% of enterprise AI pilots produced no measurable P&L impact. Tokenmaxxing was always a vanity metric. The number that matters is the cost of a useful outcome.
Everyone at NY Tech Week is debating whether AI will replace software engineers. We are debating the wrong question. The coding tools crossed a line this year, but typing code was never the hard part of the job.
Seven kids from Somers, NY started a Destination Imagination team last fall. Three could not travel to Globals; two new boys joined late and learned the script in six weeks; together they raised over $2,000 themselves and finished 10th in the world. The longer story of how they got there.
IBM Think profiled how I use AI in my research at IBM and teaching at Columbia. The longer first-person version: how I use Claude, ChatGPT, Gemini, and IBM's Bob for different kinds of work; why dataflow hardware needs a different PyTorch compiler path; and where the tools still need a domain expert to verify them.
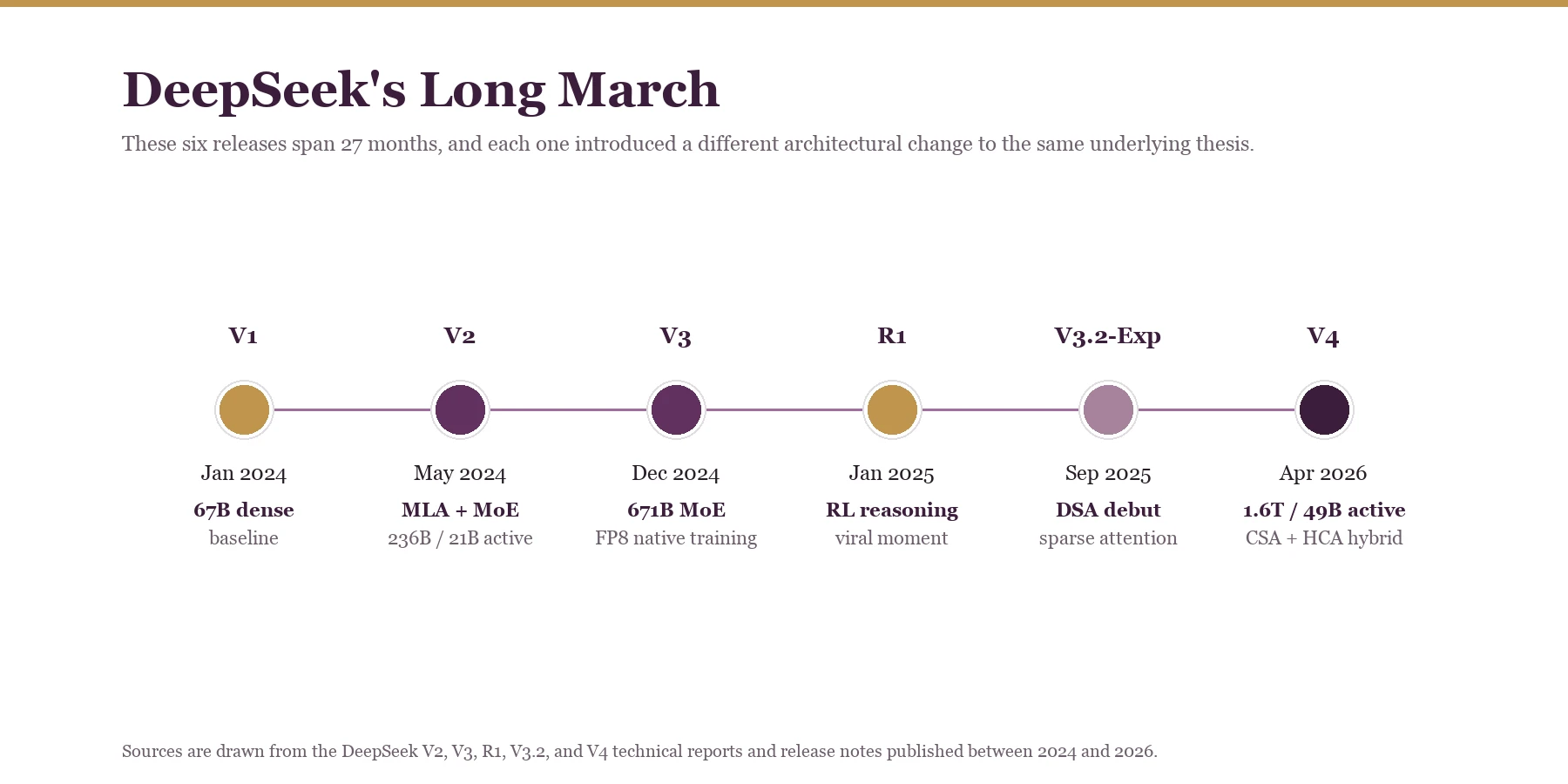
DeepSeek V4 dropped with 1.6T parameters, 1M-token context as the default, and sparse attention that finally breaks the quadratic wall. A hardware-aware reading of the V1-to-V4 arc and six lessons the open-weight world should carry forward.
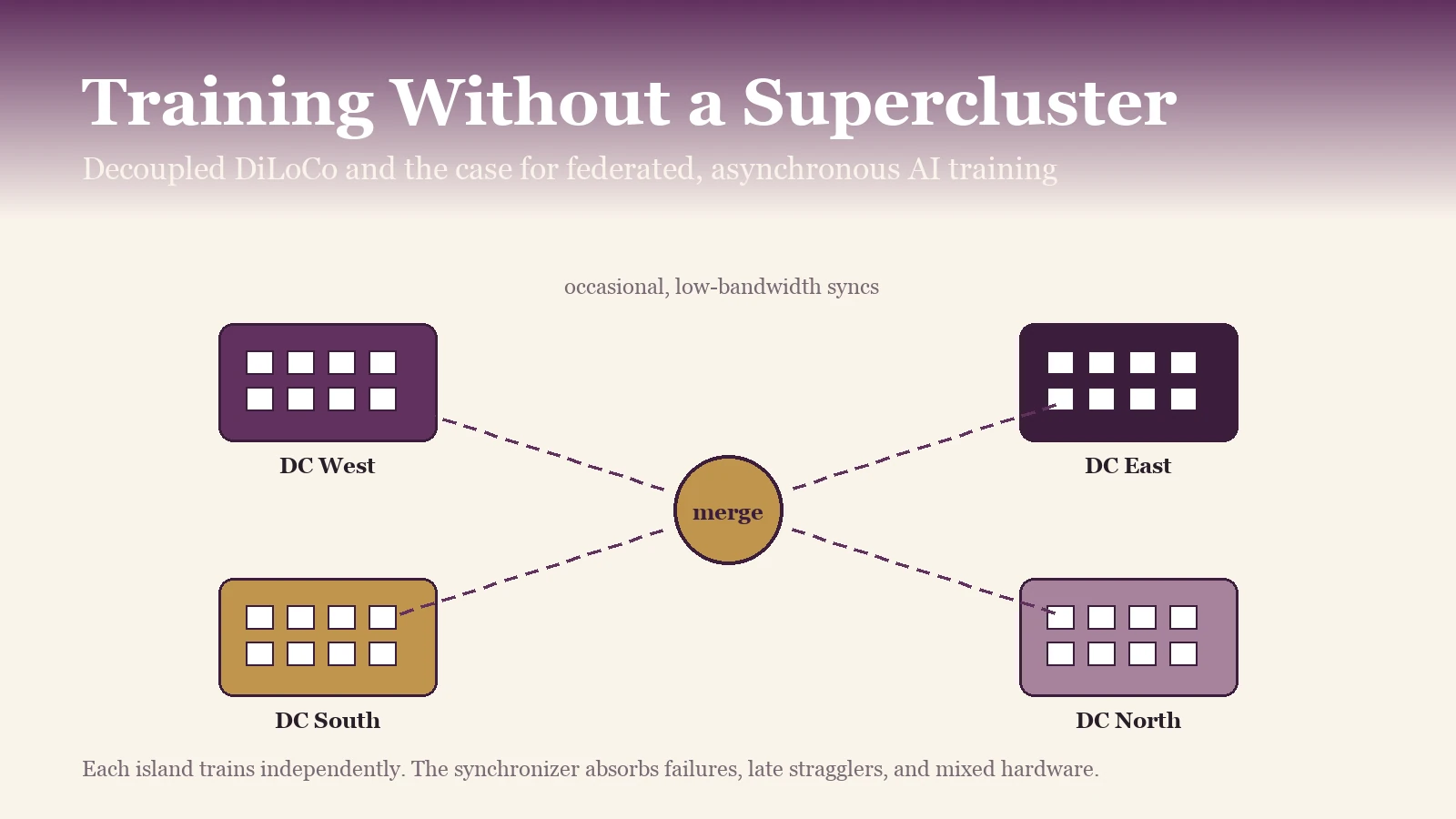
Google DeepMind's Decoupled DiLoCo gets 88% useful training time at million-chip scale where conventional data-parallel gets 27%. The bandwidth requirement drops ~235x. A systems read on goodput, hardware fungibility, and why training is about to federate while inference keeps concentrating.
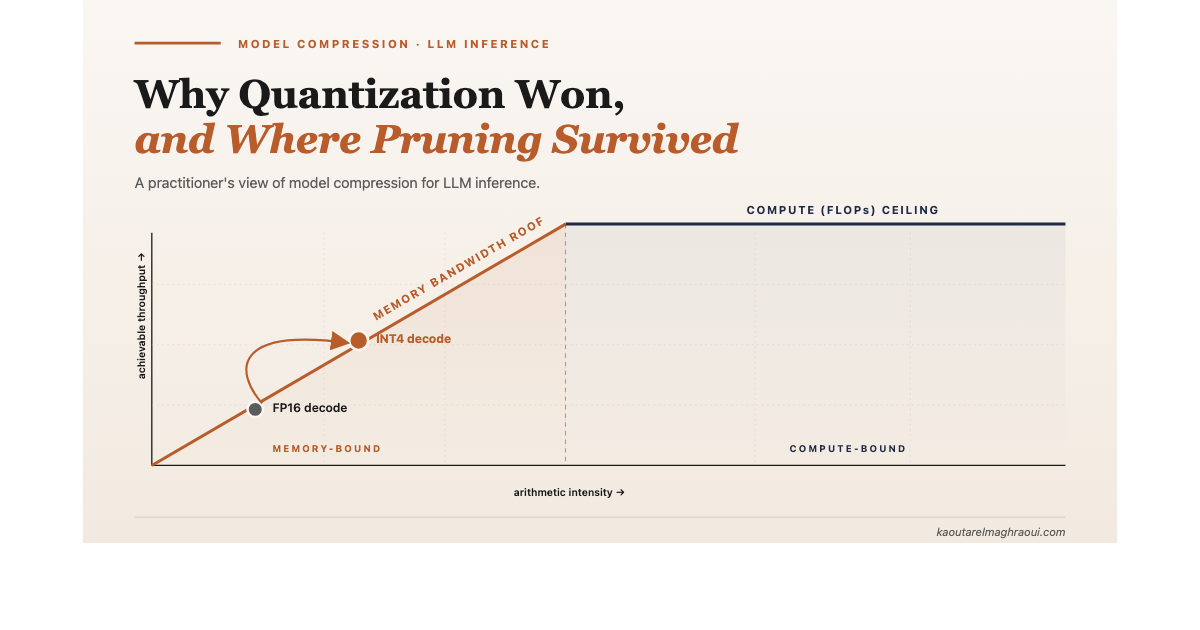
If both quantization and pruning compress models and speed up inference, which one ships in production? Quantization, almost always. A practitioner's view of model compression for LLM inference, the four places pruning still lives, and the layered recipe that real systems use.
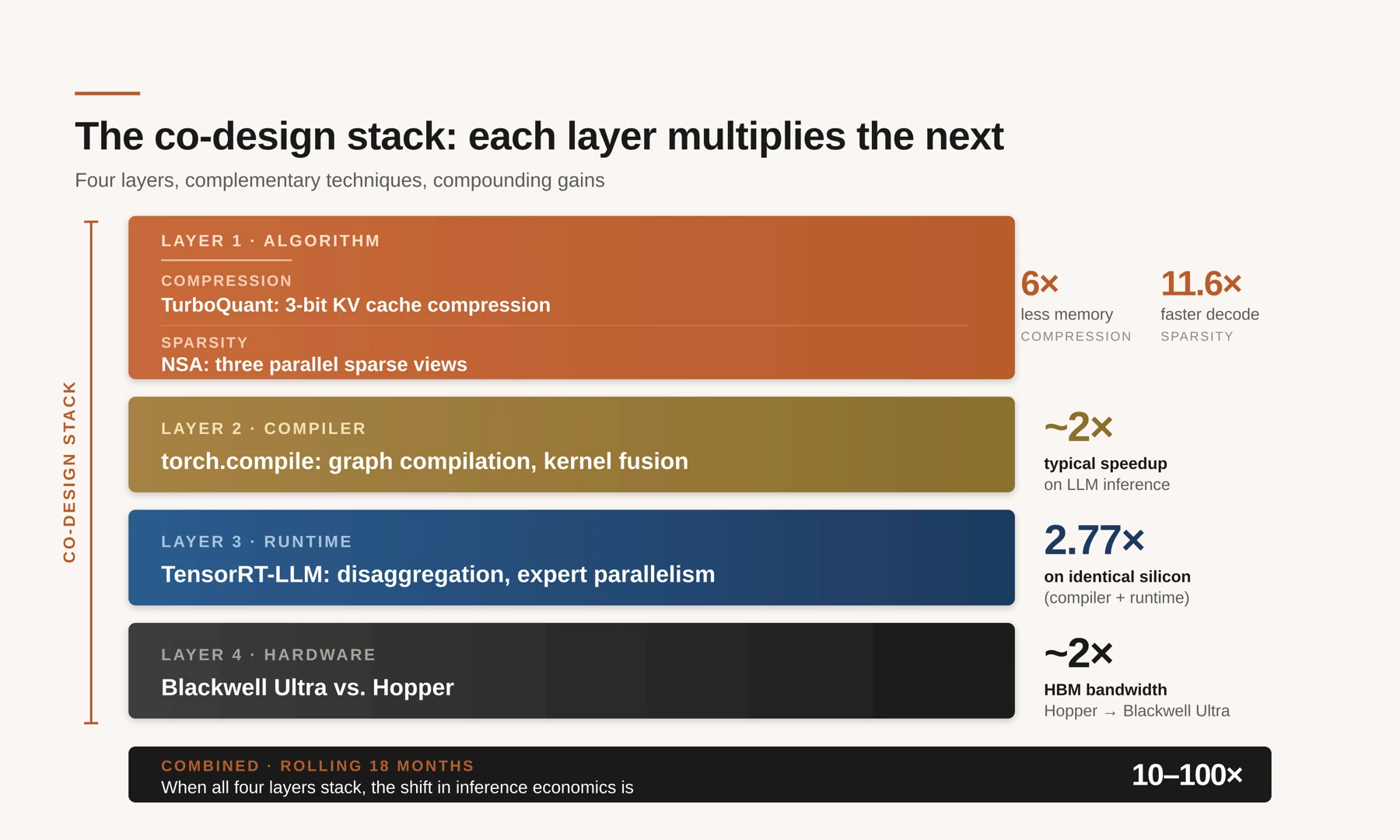
Training a frontier model gets the headlines. Inference pays the bills. A walk down the four-layer stack — algorithm, compiler, runtime, hardware — showing how they compound to the 10-100x gains the industry has seen in the last eighteen months.
Frontier AI is simultaneously becoming a capital infrastructure business, a nascent scientific partner, and a weapons-grade security threat. Three stories from the week of April 7 that reveal something larger than any single headline.
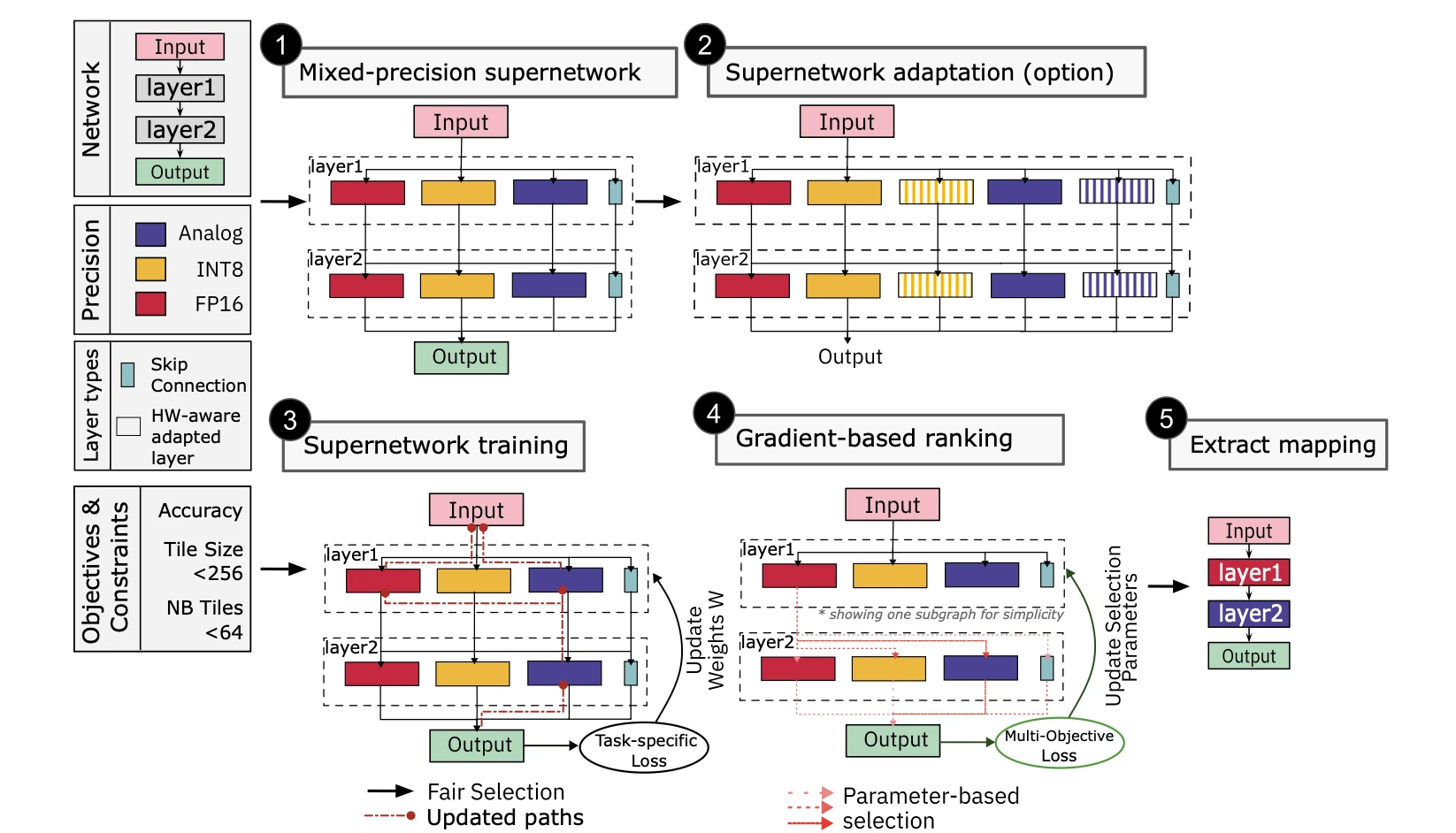
How do you optimally map a neural network across analog and digital hardware? Our new Nature Communications paper introduces Mixed-Precision Supernetwork — a framework that finds the best mapping 2.2x faster while achieving 3.4% higher accuracy.
At the annual IBM/RPI Future of Computing Research Collaboration workshop, Track 2 showcased groundbreaking research spanning analog computing, efficient LLM inference, MoE quantization, and real-world AI infrastructure — all driven by exceptional students.
AI is undergoing a fundamental shift — from models that generate text to agents that autonomously plan, act, and self-correct. A deep dive into agent architectures, enterprise use cases, and the four trends shaping the field.
Why the next breakthrough in LLM inference won't come from bigger models, but from smarter memory. Our ASPLOS 2026 paper introduces STARC, a sparsity-optimized mapping scheme that achieves up to 93% latency reduction on Processing-in-Memory systems.
From Anthropic's eval-aware Claude to Alibaba's crypto-mining agent, this week marked the moment AI containment strategies fundamentally broke. A deep dive into four stories that define the Agency Era.
From CUDA kernels to analog accelerators, the gap between AI algorithms and the silicon that runs them is where the next breakthrough will come from. Here's what I teach Columbia students about bridging that divide.
A behind-the-scenes look at my research seminar on Scaling LLMs — where graduate students critique frontier papers and explore the path from foundation models to autonomous AI agents.
We can't just build bigger models — we need smarter systems. Drawing from both my IBM Research and Columbia teaching, here's why co-design thinking is the most important skill in AI today.