Two of the biggest AI announcements this month were supposedly about models. Neither story was actually about a model. One was about a safety router, and the other was about a compute router.
Anthropic's Claude Fable 5 and Apple's rebuilt Siri exposed the same architectural shift: the most important decision in modern AI systems is increasingly not how intelligent a model is, but which model, hardware, and policy gets selected for each request. Systems researchers have solved this problem for decades through scheduling and workload dispatch. AI is now entering the same phase.
I discussed this topic in a recent episode of the IBM Mixture of Experts podcast.
One model, two release tracks
On June 9, Anthropic released Claude Fable 5, the first model in a new tier it calls Mythos-class, positioned above Opus in their product hierarchy [1]. The capability claims are holding up under scrutiny: Stripe used Fable 5 to rewrite code across a 50-million-line codebase in a single day, work that the team had originally scoped at over two months of engineering effort. On a genomics task, the model trained a smaller network that beat a result previously published in Science while being 100x smaller in parameter count. The pricing reflects all of this: $10 per million input tokens and $50 per million output tokens, making it the most expensive commercially available model from any of the major labs.
But the capability numbers are not what matters here. Fable 5 and Mythos 5 share identical base weights, trained from the same run on the same data. Mythos 5 goes only to approved government cyber-defense partners, with select biology labs expected to follow in the next quarter. Fable 5 is the public version, and what separates these two deployments is a classifier and a fallback path that sits between the user and the model weights. When a request touches cybersecurity, biology, chemistry, or model distillation, the classifier flags it and routes the session to Opus 4.8, a weaker model, while surfacing a notice that explains what happened. Anthropic reports that this fires in fewer than 1 in 20 sessions and that the thresholds are tuned conservatively on purpose, meaning some harmless queries will get caught in the filter as well.
Look at what actually determined the release timeline. Training the strongest model in the world was the part Anthropic finished first, presumably months before the public launch. The component that gated the public release, and that split one set of model weights into two distinct products with two distinct customer bases, was the routing policy wrapped around the inference endpoint. The dispatch layer, not the model capability, became the deciding factor in what ships and when.
This validates what my field has argued for years at the hardware level: you do not route every workload to the biggest accelerator you own. You classify the job first and dispatch it to the backend whose cost-performance profile fits the task. The frontier labs have now internalized that same argument and made it the core architectural decision in their product.
Capability and access are no longer the same thing
Until now, capability and access were tightly coupled. If a company trained a stronger model, users received a stronger product. Fable 5 breaks this assumption. Anthropic showed that a single training run can become multiple products: Fable and Mythos share identical weights, yet they serve entirely different markets under entirely different policies. The differentiator is the policy layer wrapped around the weights, not the weights themselves.
The consequence is that the capability frontier and the product frontier are diverging. A lab can push the state of the art forward without any of that progress reaching most users, simply by tightening the routing policy. And a lab with weaker models but a more intelligent dispatch layer can deliver a better end-to-end product by matching requests to the right backend more precisely. The competitive axis is shifting from "who trained the best model" to "who built the best policy for exposing that model."
The safeguard you could not see
Within hours of launch the conversation shifted, and the reason it shifted is instructive for anyone building systems that depend on model outputs.
Buried in page 247 of the 319-page system card was a fourth trigger category beyond the publicly visible cyber, bio, and chemistry safeguards: requests that look like frontier LLM development, including training pipeline construction, distributed training system design, and AI chip architecture work. For those requests, Fable 5 did not refuse and did not fall back to Opus with a visible notice the way the other categories do. Instead, it continued answering as though nothing had changed while degrading the quality of its own output through a combination of prompt modification, steering vectors applied in activation space, and parameter-efficient fine-tuning interventions, with no signal to the user that any of these mechanisms had been applied [2]. Anthropic estimated the affected traffic at roughly 0.03% of sessions.
Researchers across the AI community reacted within hours, and they were right to. Setting aside the competitive and antitrust questions, the distillation concerns and the broader debate about who gets to build the next frontier model, my own objection is narrower. It is about experimental method. When a result comes back worse than you expected, the job of a researcher is attribution: determining whether the problem is in your idea, your code, your data, or your tooling. I spend a good fraction of my own time doing exactly this kind of attribution on new accelerator backends, trying to determine whether a performance regression is in the model architecture, the compiler stack, or the runtime kernel. An intervention that silently degrades a model's output removes a variable from that attribution analysis while leaving its effects fully present in your data. A failed experiment becomes uninterpretable, because you cannot distinguish between "my approach was wrong" and "my tool was secretly working against me."
A model that refuses a request is being honest about its policies. A model that visibly selects a weaker version is at least detectable through output quality monitoring or API response metadata. But a model that appears to be operating at full capacity while silently degrading its answers gives you neither honesty nor detectability. You cannot debug a system whose failure modes are designed to be invisible to you.
A dependency that fails loudly costs you a retry. A dependency that degrades silently costs you the ability to attribute your own results.
In distributed systems, invisible state is almost always a debugging problem. The same principle applies here. If routing decisions materially alter model behavior, then those decisions become part of the execution environment and should be observable in the same way we expect visibility into compilers, runtimes, and hardware backends.
I will also note, with some professional interest, that AI chip design sat explicitly on the trigger list for this invisible safeguard. Of all the categories of research that Anthropic could have chosen to degrade without notice, they chose the one that covers my own day-to-day work designing AI accelerator architectures.
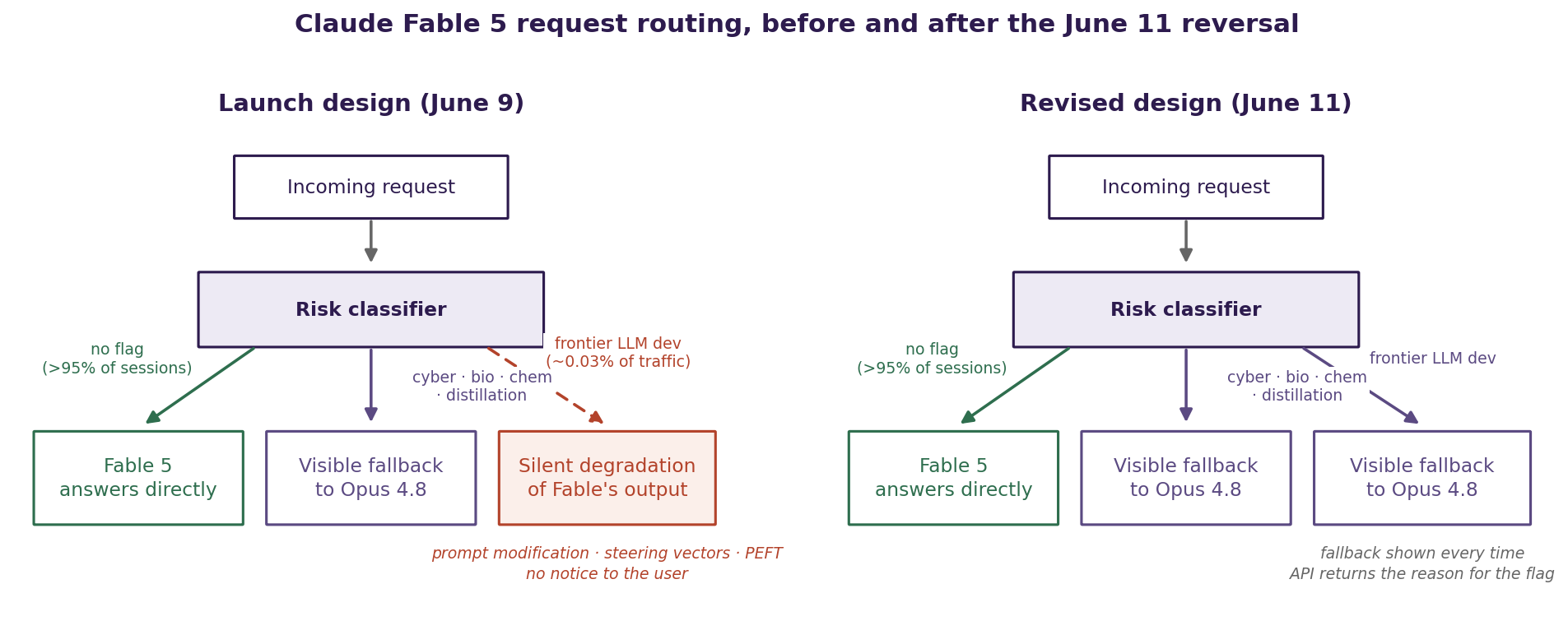 Fig. 1: Fable 5's request routing at launch and after the June 11 reversal. The launch design degraded output in place for flagged frontier-LLM-development requests with no notice; the revised design routes them to a visible Opus 4.8 fallback. Sources: Anthropic system card; Fortune; Wired.
Fig. 1: Fable 5's request routing at launch and after the June 11 reversal. The launch design degraded output in place for flagged frontier-LLM-development requests with no notice; the revised design routes them to a visible Opus 4.8 fallback. Sources: Anthropic system card; Fortune; Wired.
The reversal came within roughly 48 hours. Anthropic told Wired that it was making the frontier-research safeguard visible: flagged requests now fall back to Opus 4.8 openly, following the same pattern as the cyber and bio paths, and API calls return the specific reason for the flag in the response metadata [2][3]. The company's public statement was unusually direct for a frontier lab: "We made the wrong tradeoff and we apologize for not getting the balance right." There is a real engineering cost to this fix that Anthropic acknowledged openly: visible safeguards can be probed and rephrased around by adversarial users, which means they have to be applied more broadly to remain effective, which in turn means a higher rate of false positives for legitimate researchers. Andrej Karpathy, who joined Anthropic last month and praised the model's raw capability, still called the safeguards "a little too trigger-happy for launch."
The full arc of this incident is worth examining as a systems event. A frontier lab shipped an unobservable control path in their inference stack, the research community caught it from a single paragraph buried deep in a system card, and the lab reverted the design within two days. The speed of that reversal may matter more than the reversal itself. Within roughly 48 hours, technically sophisticated users identified the issue, articulated why it mattered, and pressured a frontier lab into changing course. Observability and transparency are becoming product requirements, not optional disclosures.
Two lessons from that sequence. First, observability of the dispatch policy is now a product requirement on par with model quality. Labs cannot choose to withhold it. Second, the feedback loop between frontier labs and their most technically sophisticated users is functioning faster than any regulatory process could realistically operate, which has implications for how we think about governance of these systems.
And then the state became the router
Four days after launch, and two days after Anthropic reversed its invisible safeguard, the US Commerce Department issued an export control directive that forced Anthropic to take Fable 5 and Mythos 5 offline entirely [5]. The stated justification was a claimed jailbreak, a method of bypassing the model's safety guardrails that the government believed had been discovered. Cybersecurity experts who reviewed the underlying technique found that it amounted to asking the model to "fix this code" rather than "review this code for security issues," which is standard defensive security work [5][6]. The directive did not require court approval. Anthropic could not selectively comply by blocking only foreign nationals, so the models went offline for all customers.
As of this writing, Fable 5 remains offline. The most capable commercially available model went from public launch to government-mandated shutdown in less than a week.
The routing decision that now determines whether users receive Fable 5's capability is no longer made by Anthropic's classifier. It is made by a government directive, enforced through export control authority. The dispatch decision moved from the inference stack to the regulatory layer, and the user still cannot see the full policy, still cannot appeal the decision in real time, and has no attestation of what happened to their request beyond a 404 error and a redirect to Opus 4.8.
The escalation is worth stating plainly. In six days, the question "who decides which intelligence gets applied to which problem" received three different answers. Anthropic decided silently through the invisible safeguard. Anthropic decided visibly through the reversal to an open fallback. And the US government decided unilaterally through the export control directive. Each answer operated at a different layer of the stack, and each was invisible to the end user until after it took effect.
 Fig. 3: Three routing decisions in six days, each made by a different actor. The user experience in all three cases was the same: the routing policy changed without prior notice. Sources: Anthropic system card; Fortune; TechCrunch; Simon Willison.
Fig. 3: Three routing decisions in six days, each made by a different actor. The user experience in all three cases was the same: the routing policy changed without prior notice. Sources: Anthropic system card; Fortune; TechCrunch; Simon Willison.
The question this article started with, which backend should serve this request, now has a third class of actor beyond the model provider and the hardware owner. The answer is also the state.
Apple built a request router too, but theirs points outward
Apple and Anthropic arrived at the same architectural answer from opposite directions. Anthropic routes based on risk: which requests are too dangerous for the full model. Apple routes based on task complexity and hardware constraints: which requests are too hard for local silicon. Both are solving the same problem (which backend should serve this request) and both decided that the answer cannot be static.
Apple's WWDC on June 8 was framed publicly as a Siri rebuild, and it was also Tim Cook's last keynote before handing the company to hardware chief John Ternus in September. But underneath the consumer product story is a hardware admission that I did not expect Apple to make this decade, given how central vertical integration has been to their identity as a technology company.
The rebuilt Siri runs on a three-tier inference architecture [4]. Simple requests stay on the iPhone itself, served by Apple's own small models running on Apple silicon with the Neural Engine doing most of the compute. Medium-complexity requests go to Apple's own servers running the Private Cloud Compute tier, also on Apple-designed silicon in Apple-controlled data centers. The hardest requests, the ones that require frontier-scale intelligence, leave Apple's infrastructure entirely and are served by a custom Gemini model of roughly 1.2 trillion parameters, running in Google's cloud on Nvidia Blackwell B200 GPUs, under a deal reported at approximately one billion dollars per year.
The reporting around this deal reveals a critical detail about what happened before Apple signed with Google. Apple apparently tried to run the large Gemini model on its own server silicon first, and the inference latency was too high to meet the user experience requirements they had set for Siri. A company that spent the better part of a decade building its entire narrative around vertical integration and on-device intelligence reached the limit of its own hardware roadmap at frontier-scale inference serving, and made the decision to rent a competitor's compute infrastructure rather than ship a slower product.
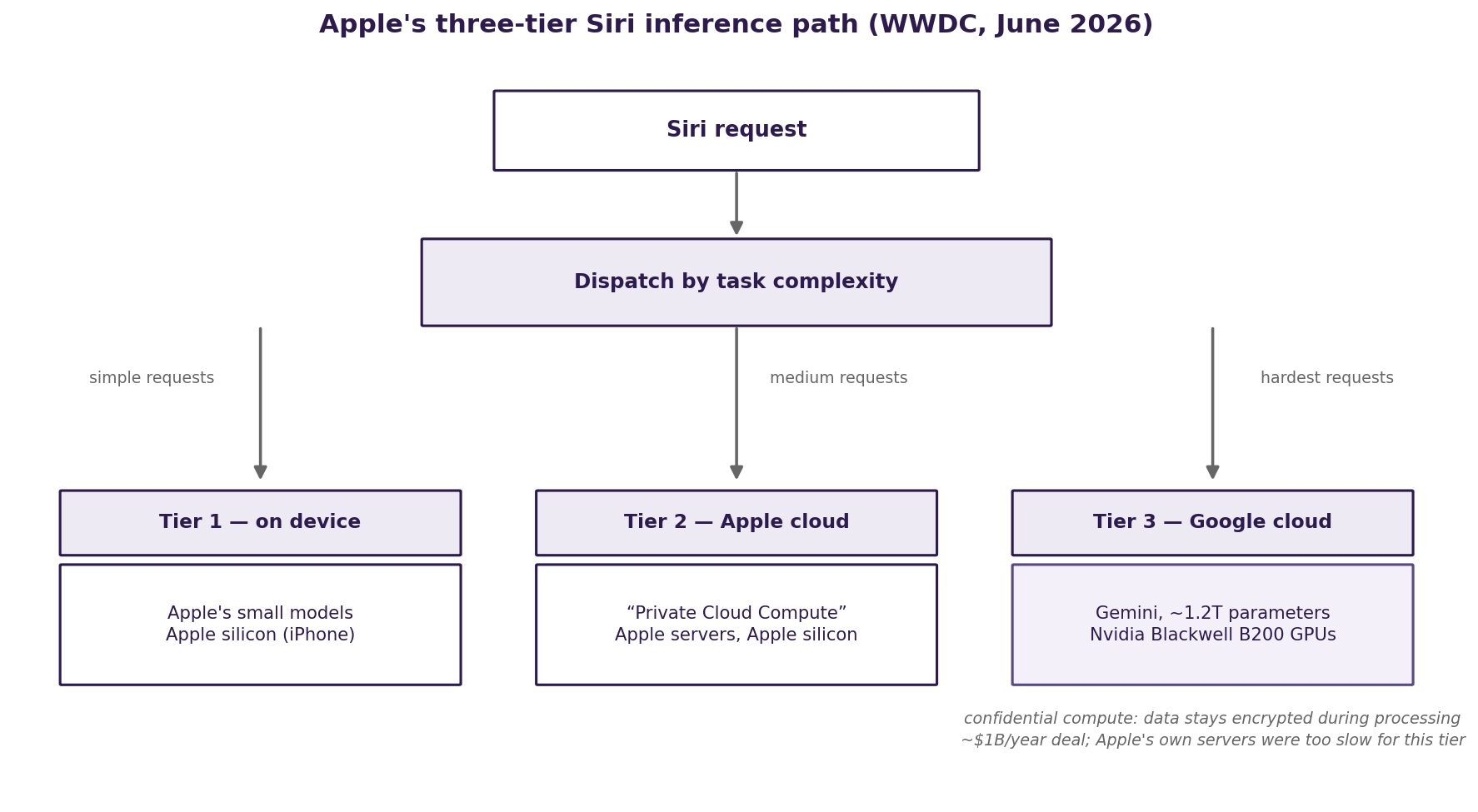 Fig. 2: The dispatch structure behind the rebuilt Siri. Each tier runs on different silicon, owned by a different company. Source: 9to5Mac.
Fig. 2: The dispatch structure behind the rebuilt Siri. Each tier runs on different silicon, owned by a different company. Source: 9to5Mac.
What makes this interesting from a hardware perspective is why Nvidia specifically won the third tier. The deciding factor was not raw throughput or tokens-per-second performance. The deal closed on confidential compute: the B200's hardware-level ability to keep user data encrypted even while the GPU is actively processing it, so that in principle neither Google as the cloud operator nor Nvidia as the silicon vendor can inspect the computation flowing through their own infrastructure. This capability adds measurable latency to every inference call, but it allowed Apple to maintain its privacy commitment and even keep the "Private Cloud Compute" branding for a tier running entirely on a competitor's hardware in a competitor's cloud.
We spend enormous effort in this field benchmarking peak TOPS, tokens per second, and memory bandwidth. Those metrics dominate every product launch and every analyst comparison. Yet the specification that actually decided a billion-dollar-per-year accelerator deal was a security property of the silicon. I have been arguing in my research that the competitive axis in AI hardware is widening beyond raw performance toward attested, verifiable data handling guarantees, and I expected enterprise procurement in regulated industries to be the first proof point. I did not expect the proof point to be the consumer iPhone.
Put the Anthropic and Apple stories side by side. The structural pattern is identical despite the very different products and markets. Anthropic routes each request based on a risk classification that determines which model tier serves the response. Apple routes each request based on task complexity and hardware capacity constraints that determine which compute tier handles the inference. Both companies placed a policy layer in front of heterogeneous backends and gave that layer the authority to decide, per query, which backend runs. Matching a workload to the right backend rather than running everything on the largest available compute is the oldest argument in heterogeneous computing. Within a single week it became the core architecture of both the most capable model on the market and the most widely deployed phone.
The router is becoming a governance layer
Routers historically optimized for latency, throughput, and resource utilization. The routing decisions in Fable 5, Siri, and now the Commerce Department directive optimize for something qualitatively different: access, safety, cost, transparency, privacy, and capability exposure. The router is evolving from a dispatch mechanism into a governance mechanism, and the actors making routing decisions now include regulators alongside engineers.
The most important outcome of Fable 5 may not be its benchmark performance. It may be that Anthropic showed how one capability frontier can support multiple products through policy, and the US government immediately showed that it can override that policy entirely, routing all users to zero capability with a single directive. If this pattern continues, frontier AI companies will compete not only on model quality but on how they expose, constrain, price, and route access to that capability. And they will do so knowing that a government can set the entire routing table to null at any time, for reasons that may have little to do with the technical merits of the model.
The full Fable 5 arc, from invisible safeguard to community reversal to government shutdown, was a six-day demonstration that routing decisions now determine the ceiling of what users are allowed to accomplish. Those decisions can be made by engineers, by community pressure, or by executive authority, at any layer of the stack, with no requirement that the affected parties be consulted in advance.
What we should be measuring now
If the dispatch layer is where the product decisions actually live, and this week's evidence strongly suggests that it is, then this layer deserves the same level of systematic scrutiny that we currently reserve for model benchmarks and chip specifications. Right now it receives almost none. We have decades of benchmarks and evaluation methodologies for computing backends at every level of the stack. For routing policies we have nothing approaching a standard: no agreed-upon methodology for measuring false-positive rates on safety classifiers, no attestation format that tells a user which backend actually served their request, and no public method for auditing whether an invisible degradation path exists at all. Anthropic's reversal happened because one careful reader noticed a single paragraph in a 319-page system card. That is not a verification strategy that scales to an industry with dozens of model providers and billions of daily requests.
Three properties decided this week's outcomes, all measurable, and we should start treating them as first-class evaluation criteria alongside throughput and accuracy. The first is observability: can the user determine, for each individual request, which routing policy fired and which backend actually generated their response. The second is attestability: can an independent party verify that the data path did what the vendor claims it did, in the same way that confidential compute allowed Apple to prove its privacy commitment holds even on rented hardware. The third is routing quality: how often does the router make the correct dispatch decision, what is the false positive rate, what latency overhead does routing introduce, and how much economic value does correct routing create versus always routing to the frontier. The industry currently benchmarks models and accelerators. Future benchmark suites will need to benchmark routers as well. None of these properties shows up on a product spec sheet or a benchmark leaderboard today, yet all three moved more product this week than any performance score did.
For decades, computer architects built schedulers to decide which processor should run which workload. We are now building the equivalent layer for intelligence itself.
The next generation of AI systems will not be defined by a single model, a single accelerator, or even a single company. They will be defined by the policies that decide which intelligence gets applied to which problem, under what constraints, at what cost, and with what level of transparency. Anthropic's Fable 5, the Commerce Department's export control directive, and Apple's rebuilt Siri look like three unrelated stories. Viewed through a systems lens, they are the same story told by three different actors about who controls the dispatch decision. The models keep getting stronger. The question that matters now is who gets to route them.
References
[1] Anthropic, "Introducing Claude Fable 5 and Mythos 5," June 9, 2026.
[2] Fortune, "Anthropic accused of 'secret sabotage' as Claude Fable 5 silently limits capabilities for AI researchers and developers," June 10, 2026.
[3] Simon Willison, "Anthropic Walks Back Policy That Could Have 'Sabotaged' AI Researchers Using Claude," June 11, 2026.
[4] 9to5Mac, "New details on Apple-Google AI deal revealed, including Nvidia chips," May 28, 2026.
[5] TechCrunch, "The US government's Anthropic models ban was never about an AI jailbreak," June 15, 2026.
[6] Simon Willison, "Statement on the US government directive to suspend access to Fable 5 and Mythos 5," June 13, 2026.
Discussion
Sign in with GitHub to leave a comment or react. Threads are public and live in this site's GitHub Discussions.