Our Nature Communications Paper: Efficient Mapping of Deep Learning to Mixed-Precision Hardware
I'm excited to share that our paper, Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation, has been published in Nature Communications.
This work is the result of a collaboration across IBM Research labs in Zurich, Yorktown Heights, and Almaden, led by Hadjer Benmeziane with co-authors Corey Lammie, Irem Boybat, Malte Rasch, Manuel Le Gallo, Athanasios Vasilopoulos, Hsinyu Tsai, Geoffrey W. Burr, Vijay Narayanan, Kaoutar El Maghraoui, and Abu Sebastian.
The Problem: Mapping Neural Networks to Heterogeneous Hardware
Heterogeneous accelerators that combine specialized analog and digital compute units are one of the best paths to energy-efficient AI inference. Analog In-Memory Computing (AIMC) can perform matrix-vector multiplication directly within memory arrays, cutting data movement overhead and energy consumption by a wide margin. The trade-off: analog compute introduces noise from device variability, conductance drift, and circuit imperfections. Different layers of a neural network have different sensitivities to this noise, so naively mapping everything to analog hardware degrades accuracy.
How do you decide which layers should run on analog, which on digital (INT8, FP16), and how should you adapt the model to best exploit the hardware? Prior approaches relied on heuristics or exhaustive search. Both are either suboptimal or impractical for large models.
Our Approach: Mixed-Precision Supernetwork (MPS)
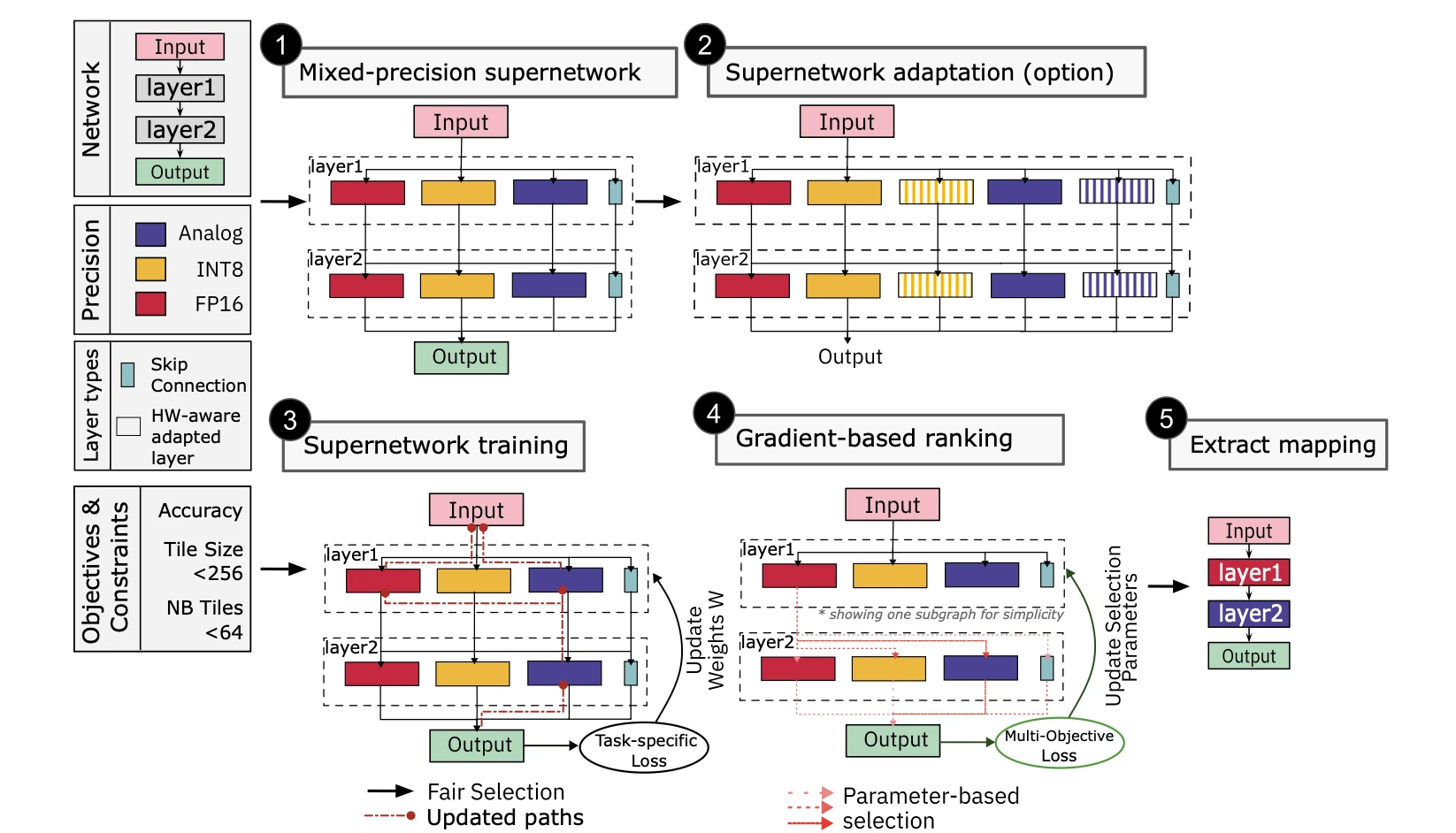
We introduce Mixed-Precision Supernetwork (MPS), a principled approach that treats this mapping problem as a neural architecture search. The idea: build a single supernetwork that encapsulates all possible precision choices (analog, INT8, FP16, skip) for each layer within a unified structure. This eliminates the need for exhaustive evaluations of individual subnetworks and cuts mapping time by about 2.2x.
The MPS framework: (1) construct a mixed-precision supernetwork, (2) optionally adapt layers for hardware, (3) train with fairness sampling and progressive noise scaling, (4) gradient-based ranking across objectives, (5) extract the optimal mapping.
The framework works in five steps:
-
Construct the supernetwork — each layer gets candidate operations for every precision level, including a pass-through (skip) option for pruning.
-
Hardware-aware model adaptation — we introduce adapted layers that are specifically designed to maximize utilization of analog tile resources without increasing energy or latency. For example, resizing fully-connected layers to match analog tile dimensions, or adapting attention blocks to fully occupy computational tiles.
-
Train with a specialized mechanism — fairness sampling ensures all precision options get trained equally; progressive noise scaling gradually introduces analog noise during training; quantization-aware training handles INT8 precision.
-
Gradient-based multi-objective ranking — a Pareto-based ranking evaluates each configuration simultaneously across accuracy, analog MAC ratio (energy efficiency), and digital weight size (memory footprint).
-
Extract the optimal mapping — the final mapping is extracted from the Pareto front, balancing all objectives.
Key Results
We evaluated MPS on three edge computing benchmarks: image classification (CIFAR-10), object segmentation (COCO), and question answering (SQuADv1). We compared against ODiMO, LionHEART, and Harmonica on architectures from ResNet and MobileNetV2 to Adapter-ViT and MobileBert.
Here's what stood out.
On CIFAR-10 with ResNet20, MPAAS hits 94.2% accuracy, which actually surpasses the full digital FP32 baseline (92.0%). That's a counterintuitive result worth unpacking. The accuracy gain comes from hardware-aware layer adaptations that widen fully-connected layers to match analog tile dimensions (e.g., 256 rows), growing parameters from 0.26M to 0.86M. The model gets slightly bigger, but it's using the hardware more efficiently, and that translates directly into better accuracy. By comparison, ODiMO reaches 84.3% and LionHEART 84.25%.
On COCO with VIT-Adapter-S, MPAAS reaches 48.3% mIoU — up from 42.8% for fully analog mapping — while running 69% of MAC operations on analog and keeping the digital weight footprint at just 3.8 MB. On SQuADv1 with MobileBert, MPAAS gets 92.1% F1-score with 68% analog MAC ratio, nearly matching the full digital baseline (91.3% F1) while cutting digital memory to 26.1 MB. LionHEART reaches only 89.56% F1 with fewer analog resources used.
The speed advantage matters too. MPS finds optimal mappings ~2.2x faster than existing methods on average. Heuristic-based approaches like LionHEART exceed 16 hours for larger architectures. They just don't scale. Because MPS trains a single supernetwork rather than evaluating individual subnetworks, the search time stays manageable even on models like BERT-base where the search space is enormous.
What Each Component Contributes
One thing I appreciate about this work is the ablation study — it's not a single monolithic system where you can't tell what's doing the heavy lifting. Here's the progression on ResNet20:
| Configuration | ResNet20 (Acc%) | ResNet50 (mIoU%) | MobileBert (F1%) |
|---|---|---|---|
| MPS (baseline) | 81.9 | — | — |
| + QAT | 84.5 | — | — |
| + QAT + HW-aware training | 87.3 | — | — |
| + QAT + Sparsity + HW-aware | 90.8 | 56.4 | 89.3 |
| MPAAS (full) | 92.4 | 58.7 | 91.6 |
Every component pulls its weight: quantization-aware training, hardware-aware noise modeling, skip connections for sparsity, and the hardware-aware layer adaptations. You can't drop any of them without losing meaningful accuracy. The full MPAAS configuration, the one that integrates all three strategies, consistently wins across all architectures and tasks.
From Proxy Metrics to Real Hardware
A fair criticism of mapping approaches is that they optimize proxy metrics (analog MAC ratio, digital weight size) but what about actual latency and energy on real hardware? We addressed this by simulating all extracted mappings on the 3DCiM-LLM-Inference Simulator, using a single-tier heterogeneous system with up to 64 analog tiles of 512x512 dimension, modeled after HERMES measurements (0.65 ns/MAC, 0.35 pJ/MAC for analog; 1.6 ns/MAC, 1.4 pJ/MAC for digital).
The proxy-metric improvements do translate. On ResNet20, MPAAS runs at 1.15 ms latency and 89.7 uJ/sample, compared to 2.30 ms and 232.8 uJ for full digital FP32. That's roughly 2x faster and 2.6x more energy-efficient. Against other mapping methods, MPS achieves up to 1.3x latency reduction and 20-25% lower energy per sample over LionHEART and ODiMO, while matching or beating their task-specific accuracy.
What the Mappings Tell Us About Architecture
What I find particularly interesting is what the optimized mappings reveal about neural network structure. Patterns that aren't obvious from the architectures alone.
In CNNs, the first and last layers consistently land on digital precision. That makes sense: they're the most sensitive to noise, and getting them wrong cascades through the rest of the network. But the middle layers, especially in deeper networks like ResNet50, overwhelmingly favor analog. That's where the energy savings come from. Skip connections are another story entirely. They strongly prefer INT8 or FP16, which makes intuitive sense: maintaining precision in residual pathways prevents error accumulation.
Transformers show a different pattern. Feedforward, attention, and intermediate layers favor analog. These are large matrix multiplications that map well to AIMC tiles. But the output layer consistently prefers FP16, and the bottleneck layer in MobileBert favors INT8. The search is discovering, through gradients, the layer-level noise sensitivity that would be extremely tedious to characterize by hand.
And one more thing: the optimal mappings from smaller models can serve as blueprints for larger variants of the same architecture. We found that mapping insights from the smallest BERT variant transfer well to larger BERT models, which cuts the search cost considerably when scaling up.
Why This Matters
The energy and latency costs of AI inference are becoming a first-order concern. Not a theoretical worry, but a practical constraint that shows up in every deployment conversation. Mixed-precision hardware, combining the energy efficiency of analog compute with the precision of digital, is one of the most promising paths forward. But without a principled way to map models to this hardware, we're leaving performance on the table.
MPS gives us that principled approach. It works across CNNs and transformers, it's hardware-agnostic, and the improvements hold up when validated on realistic hardware simulation, not just proxy metrics. A step toward making heterogeneous AI accelerators practically deployable, not just theoretically appealing.
The code and data are open-source on GitHub.
Read the full paper: Nature Communications (2026)
Discussion
Sign in with GitHub to leave a comment or react. Threads are public and live in this site's GitHub Discussions.