Redefining the Future of AI through HW-SW Synergy: Highlights from IBM/RPI FCRC 2025

On April 1, 2026, researchers from IBM and Rensselaer Polytechnic Institute (RPI) gathered at the RPI campus for the FCRC 2026 Annual Workshop — a full day of keynotes, lightning talks, and a poster session to celebrate the achievements of our 2025 collaboration and chart the course for the year ahead.
The IBM-RPI Future of Computing Research Collaborations (FCRC) is a multi-year joint partnership to expand collaboration between the two organizations in key areas of computational research — fundamental AI, AI hardware-software co-design, microelectronics, and quantum computing. Housed within RPI's Future of Computing Institute (FOCI), the program has had remarkable impact: 100 projects funded, 54 unique principal investigators, and 161 student opportunities created since its inception. In 2026 alone, the program awarded 35 projects across four tracks (10 in Track 1: AI Algorithms, 10 in Track 2: AI HW-SW Co-Design, 8 in Track 3: Semiconductor Technology, and 7 in Track 4: Quantum Computing).
The day opened with welcome remarks from Dr. John E. Kolb, VP and Head of FOCI, and Sudhir Gowda, Director of Academic Research Collaborations at IBM Research. The IBM strategy keynote was delivered by Dr. Jeff Burns, Director of AI Compute and the IBM Research AI Hardware Center, who laid out the strategic imperative for hardware-software co-design: compute demand for AI training is doubling every six months, agentic AI workloads are making inference a repeatedly-called subroutine, and the cost of running generative AI remains staggeringly high. His message was clear — accelerator and system design innovation, and technology-accelerator co-design, are keys to addressing AI's opportunities and challenges. Burns highlighted how IBM's Spyre Accelerator (AIU) has already transitioned from research to product, integrated into the IBM z17 mainframe and Power11 systems — delivering 300+ TOPS on a PCIe-attached card with 128GB of LPDDR5 memory.
I'm proud to share the highlights from Track 2: Hardware-Software Co-Design for Scalable and Efficient AI, which I co-lead with Professor Christopher Carothers, Chief Scientist and Director of the Center for Computational Innovations (CCI) at RPI.
With Track 2 students at the FCRC poster session (left to right): Yayue Hou, Kaoutar El Maghraoui, Junfeng Wu, and Zehao Fan.
Track 2: Where Our Research Fits
Over the past year, one thing has become increasingly clear: the bottleneck in AI has shifted from the models themselves to the systems that run them. As we push toward agentic workflows, multimodal reasoning, and real-time interaction, the pressure on memory, latency, and energy efficiency is no longer theoretical. It shows up immediately in deployment. This is exactly where hardware-software co-design stops being a research topic and becomes a necessity.
This necessitates workload-aware hardware-software co-design, where model structure, runtime, compiler, and hardware architecture are jointly optimized to achieve efficiency, scalability, and sustainability. Track 2 focuses on two complementary pillars:
-
Inference Optimization and Workload Scaling on Digital Accelerators — improving inference speed, energy usage, and system scalability for emerging AI workloads, from agentic and interactive AI to KV cache optimization and inference server co-design, particularly in the context of IBM's next-generation AI accelerators such as Spyre AIU.
-
Integrating Analog AI with the Digital Fabric — advancing the algorithmic robustness and architectural integration of analog AI, from hybrid analog-digital architectures and robust analog inference to cross-domain partitioning and end-to-end simulation, particularly in the context of IBM Analog AI technologies.
Our work this year spans four interconnected themes across these two pillars, each producing publications at top-tier venues — and each driven by exceptional student researchers.
Theme 1: Pioneering Analog Computing and Heterogeneous Memory Systems
The first pillar of our work pushes the boundaries of non-traditional computing substrates and memory hierarchies.
Analog In-Memory Training — Zhaoxian Wu (student), with Tianyi Chen, Liu Liu (RPI), Tayfun Gokmen, Omobayode Fagbohungbe (IBM), is closing the accuracy gap for large foundation models trained on non-ideal resistive elements. The key insight is that by characterizing device-dependent response functions and co-designing training algorithms around them, analog in-memory computing becomes a viable path for training — not just inference — of large-scale models. Accepted at NeurIPS '25.
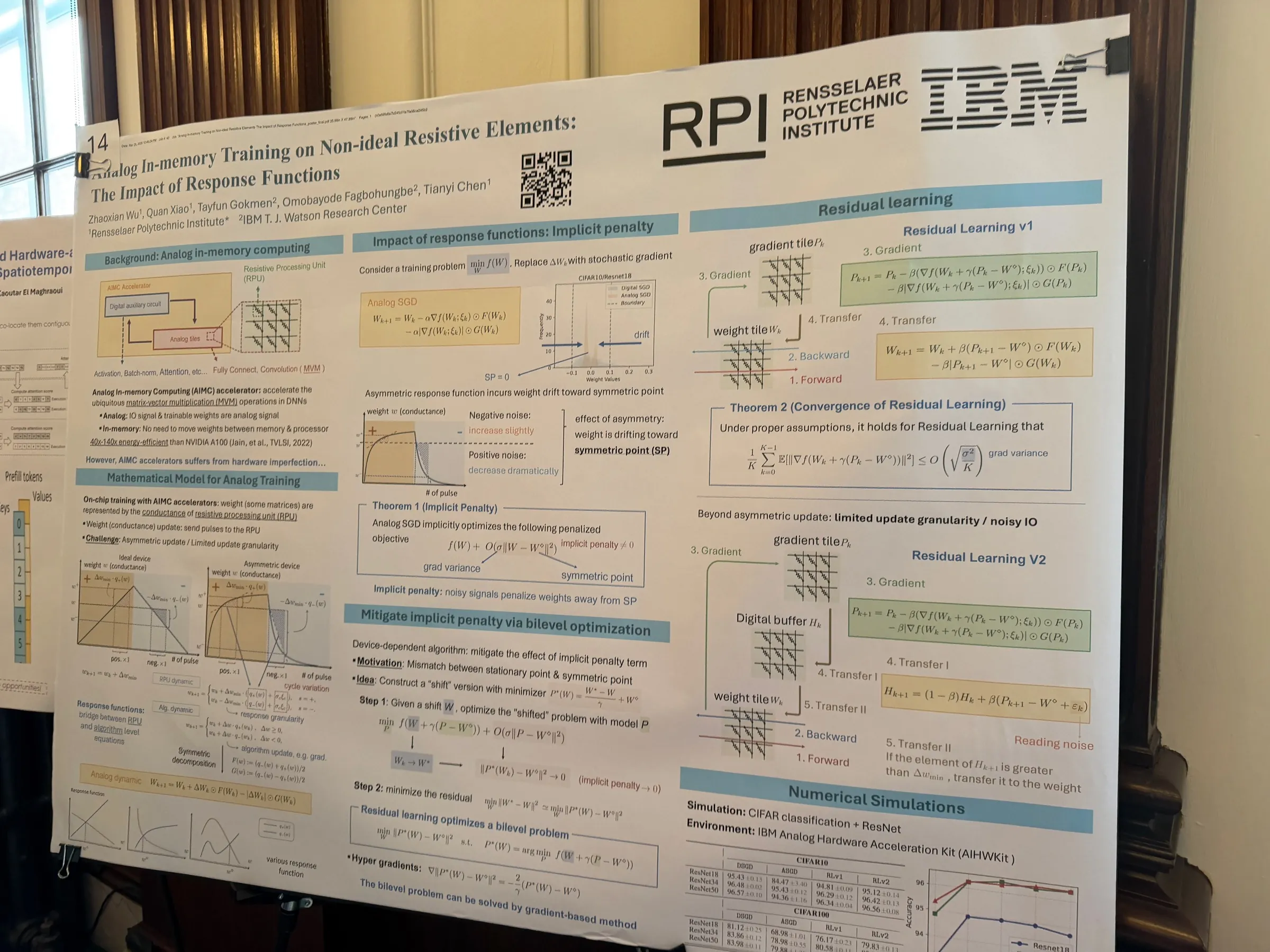 Poster: Closing the accuracy gap in analog in-memory training — the impact of response functions.
Poster: Closing the accuracy gap in analog in-memory training — the impact of response functions.
Heterogeneous Memory Optimization — Yunhua Fang (student), with Meng Wang, Tong Zhang (RPI), Kaoutar El Maghraoui, Naigang Wang (IBM), is optimizing data placement in heterogeneous memory systems to maximize throughput for large-scale AI workloads. An interesting direction this work explored is to look at KV cache placement not as a fixed system decision, but as an optimization problem. Instead of relying on heuristics, the team used simulated annealing to probe what optimal placement could look like across HBM and off-package memory. What stands out is the gap this work exposes. Current systems are leaving measurable performance on the table simply because we haven't fully explored the placement space yet. Published in IEEE Computer Architecture Letters (CAL) 2025.
 Poster: Accelerating LLM inference via dynamic KV cache placement in heterogeneous memory systems.
Poster: Accelerating LLM inference via dynamic KV cache placement in heterogeneous memory systems.
Efficient CiM Architectures — Yayue Hou (student), with Liu Liu, Meng Wang (RPI), Hsinyu Tsai, Kaoutar El Maghraoui (IBM), is developing Compute-in-Memory architectures that minimize data movement and energy consumption. The innovation lies in co-analyzing LLM data distributions and analog compute-in-memory (ACIM) non-idealities to enable saliency-aware grouping (SAGE) for efficient mapping and mixed-precision ADC operation — achieving energy reduction in both ACIM computation and data transfer while maintaining high accuracy. Accepted at both ICCAD '25 and DATE '25.
 Poster: Co-designing analog AI systems and accelerators for large foundation models — saliency-aware mapping with mixed-precision ADC.
Poster: Co-designing analog AI systems and accelerators for large foundation models — saliency-aware mapping with mixed-precision ADC.
Theme 2: Advancing Efficient LLM Decoding and Inference
As LLMs grow in size and capability, the memory bandwidth bottleneck during inference becomes increasingly critical. Two projects tackle this from complementary angles.
STARC: Selective Token Access with Remapping and Clustering — Zehao Fan (student), with Yinan Wang, Liu Liu (RPI), Kaoutar El Maghraoui (IBM), has developed a sparsity-optimized mapping scheme for efficient LLM decoding on Processing-in-Memory (PIM) systems. By exploiting attention sparsity and dynamic token importance, STARC achieves dramatic latency reductions for LLM inference. Accepted at ASPLOS '26 — one of the premier venues in computer architecture.
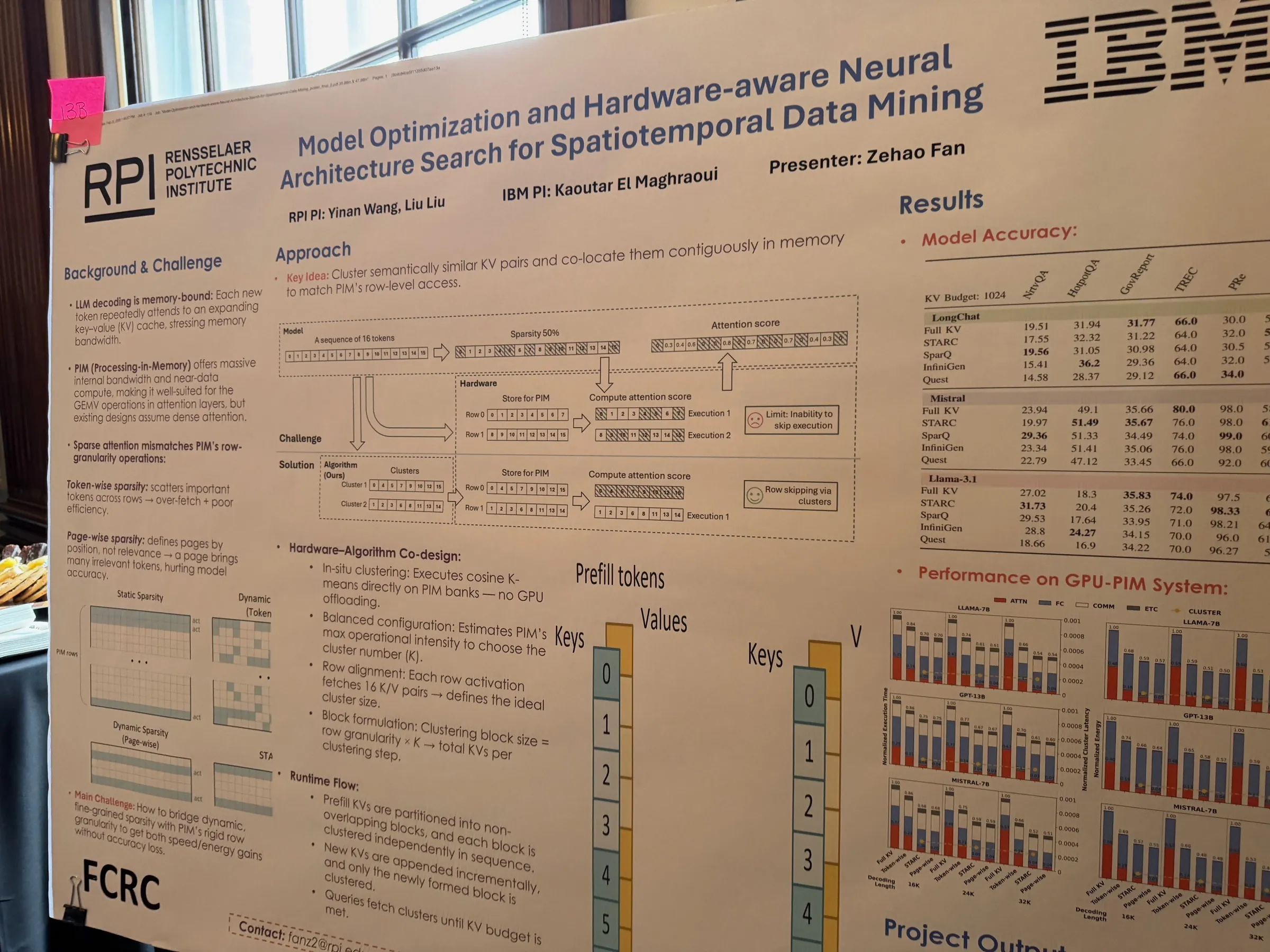 Zehao Fan's STARC poster — selective token access with remapping and clustering for efficient LLM decoding on PIM systems.
Zehao Fan's STARC poster — selective token access with remapping and clustering for efficient LLM decoding on PIM systems.
Efficient Inference via Novel Linear-type Attention — Shreenidhi Srinivasan, Anweshit Panda, and Haven Cook (students), with Yangyang Xu, George Slota (RPI), Jie Chen, Naigang Wang (IBM), are replacing softmax-based attention with novel linear-type attention mechanisms that eliminate the need for full KV caching. The approach uses stage-wise low-rank KV cache approximation combined with exponential and rational decay functions, reducing computation from quadratic to linear while preserving accuracy. The techniques can be applied to Granite 4.0 (BAMBA) models for efficient deployment on Spyre AIU accelerators.
 Poster: Enabling efficient inference and high accuracy by exploring novel linear-type attention and KV cache optimization.
Poster: Enabling efficient inference and high accuracy by exploring novel linear-type attention and KV cache optimization.
Theme 3: Democratizing Training and Securing the AI Foundation
Making AI training more accessible and building security into the hardware-software stack are two sides of the same coin.
Compressed Decentralized Training — Wei Liu (student), with Yangyang Xu, George Slota (RPI), Jie Chen, Naigang Wang (IBM), developed the DAMSCo_DaSHCo library, which introduces compressed decentralized methods for high-performance training with limited bandwidth. Published in TMLR '25.
Adversarial-Resilient Architectures (SINAI) — Zhenyu Liu (student), with Tong Zhang, Liu Liu (RPI), Swagath Venkataramani, Sanchari Sen (IBM), is building adversarial defense directly into hardware through SINAI (Selective Injection of Noise with Architectural Integration). The key innovation is a critical pathway hypothesis: by screening dominant pathways and applying approximation to non-critical ones while selectively injecting noise, SINAI achieves up to 15.24% improvement in adversarial robustness under AutoAttack compared to OAT, with up to 7.8x speedup and 5.56x better energy efficiency over a generic NPU.
Efficient MoE Quantization — M. Nowaz (student), with Meng Wang, Tong Zhang (RPI), Kaoutar El Maghraoui, Naigang Wang (IBM), tackled efficient quantization of Mixture-of-Experts models with theoretical generalization guarantees. This work was accepted at ICLR '26 and received the Best Student Poster Award at the IEEE AI Compute Symposium '25.
Cost-Effective AI Infrastructure (REACH) — Rui Xie (student), with Tong Zhang, Liu Liu (RPI), Swagath Venkataramani, Sanchari Sen (IBM), addresses the high $/GB cost of HBM by proposing REACH (Reliability Extension Architecture for Cost-effective HBM) — a domain-specific ECC architecture that pushes the raw bit error rate to 10⁻³ while maintaining 80% LLM throughput. In 7nm, REACH reduces decoder area by 11.6x and power by 60%, and can be extended to DDR, LPDDR, or CXL-attached memory. Published in IEEE CAL '25.
 Poster: Holistic algorithm-architecture co-design of approximate computing for scalable foundation models — featuring REACH (left) and SINAI (right).
Poster: Holistic algorithm-architecture co-design of approximate computing for scalable foundation models — featuring REACH (left) and SINAI (right).
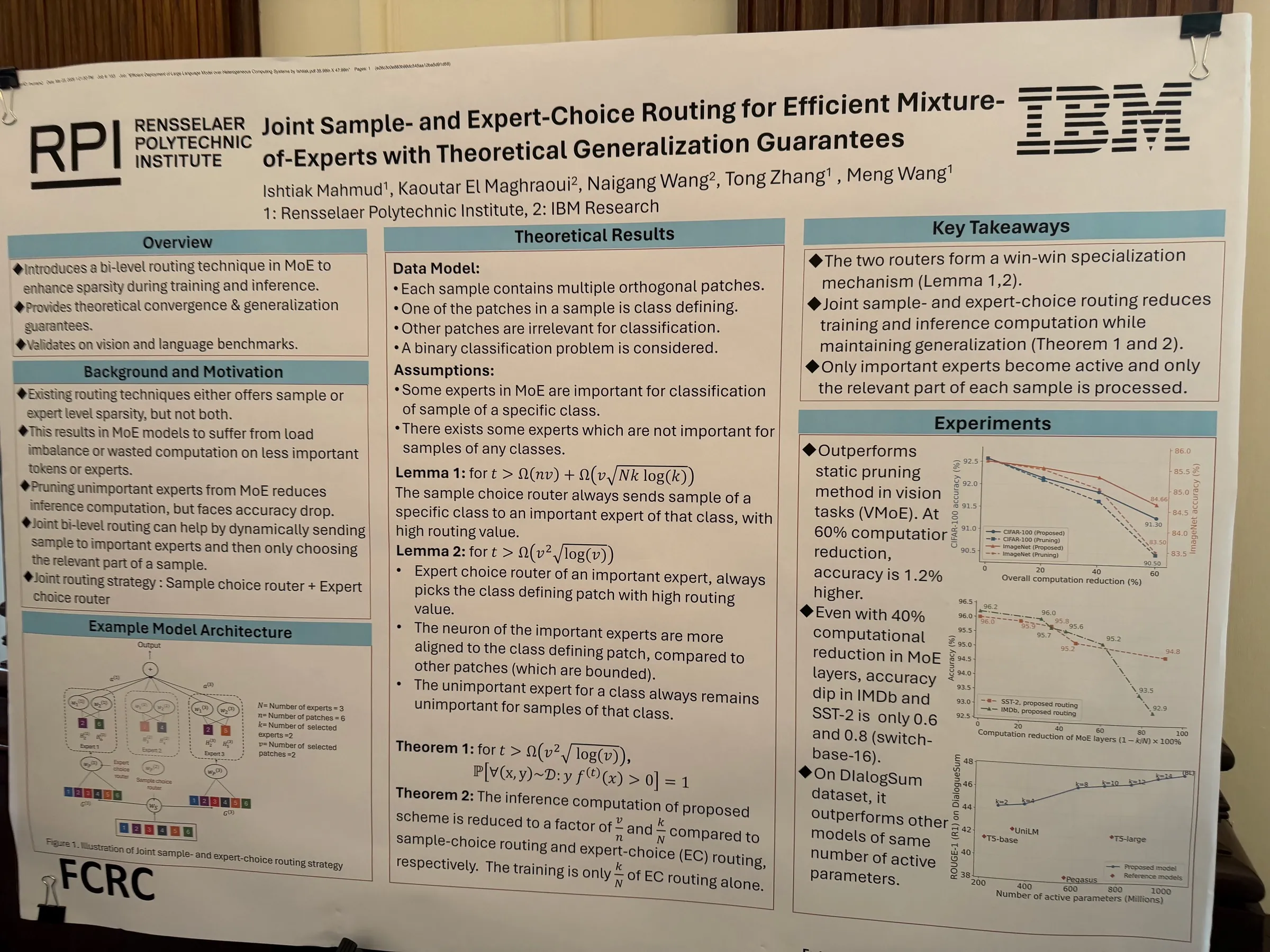 Ishtiak Mahmud's poster on joint sample- and expert-choice routing for efficient MoE with theoretical generalization guarantees.
Ishtiak Mahmud's poster on joint sample- and expert-choice routing for efficient MoE with theoretical generalization guarantees.
 Mohammed Nowaz Rabbani Chowdhury's poster on robust heterogeneous analog-digital computing of MoE models.
Mohammed Nowaz Rabbani Chowdhury's poster on robust heterogeneous analog-digital computing of MoE models.
Theme 4: Translating Innovation into Real-World Connectivity and Infrastructure
Research impact is measured not just in publications but in real-world applications. Track 2's fourth theme bridges the gap between innovation and deployment.
5G/6G Edge Connectivity — Raj Bakhunchhe and Swastik Kanjilal (students), with Ish Jain, Ali Tajer (RPI), Alberto Garcia, Sara Garcia Sanchez, Arun Paidimarri (IBM), are building a real-time mmWave beam management and communication platform for next-generation edge connectivity. The project applies physics-guided Neural Radiance Fields (NeRF) to the wireless domain, creating digital twins of mmWave propagation environments that are 2x faster than standard NeRF2 and work in both line-of-sight and non-line-of-sight scenarios. Validated with IBM's 27 GHz phased arrays and OptiTrack motion capture. Presented at GOMACTech '26.
 Poster: Bringing AI intelligence to the 5G/6G edge platform — physics-guided NeRF for mmWave beam management.
Poster: Bringing AI intelligence to the 5G/6G edge platform — physics-guided NeRF for mmWave beam management.
AI-Accelerated Medical Imaging — Ismail Erbas (student), with Xavier Intes, Vikas Pandey (RPI), Karthik Swaminathan, Aporva Amarnath, Naigang Wang, Kaoutar El Maghraoui (IBM), is accelerating real-time fluorescence lifetime imaging for guided surgery using FPGA-based deep learning and HW-SW co-design. This work produced two publications: Physics-guided deep learning model for depth and lifetime estimation at SPIE Photonics West 2025, and Advancing Fluorescence Detection and Ranging in Scattering Media with Mixture-of-Experts and Evidential Critics at the NeurIPS '25 Workshop on Imageomics.
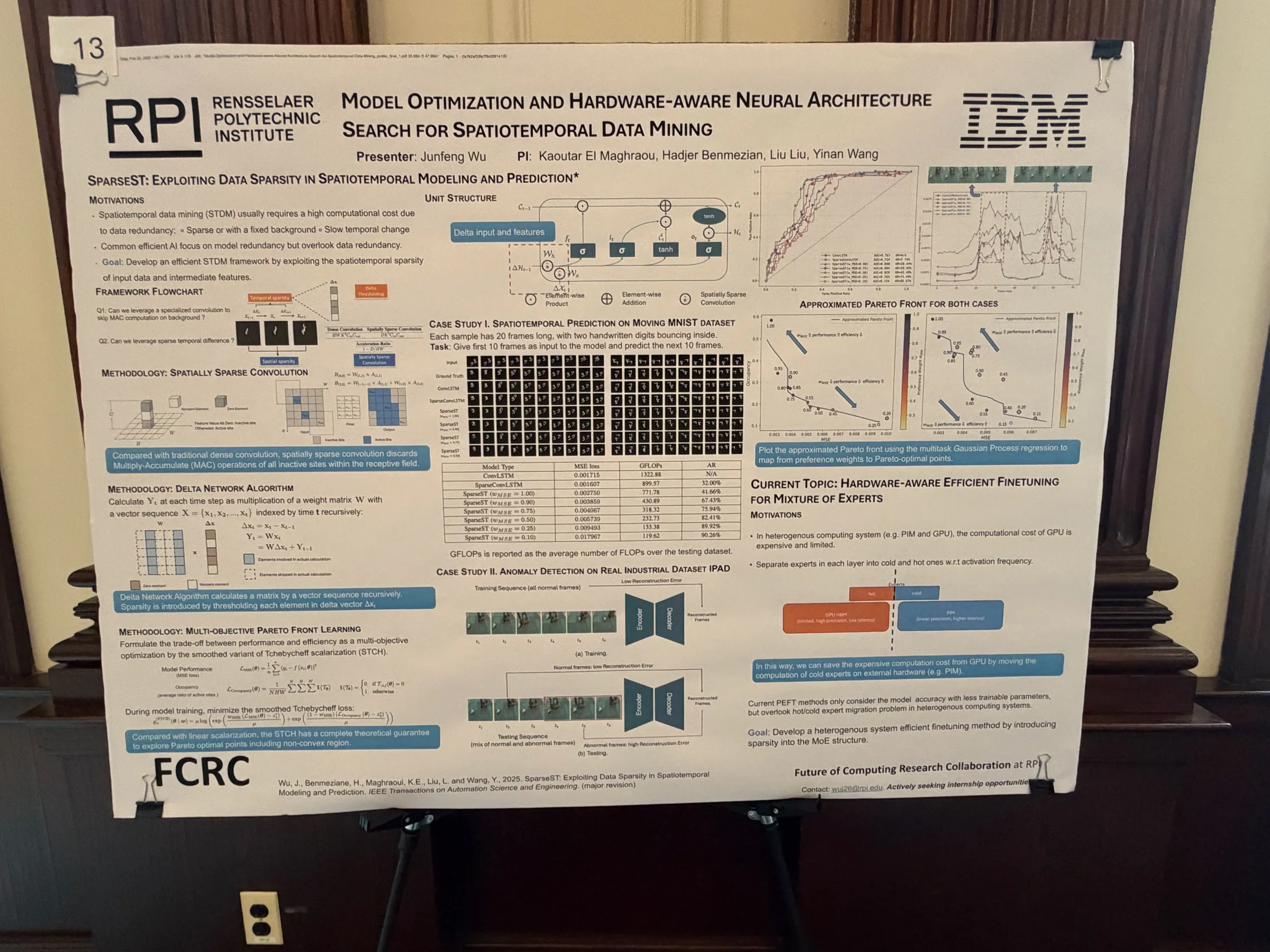 Junfeng Wu presenting the SparseST poster — exploiting data sparsity in spatiotemporal modeling and prediction.
Junfeng Wu presenting the SparseST poster — exploiting data sparsity in spatiotemporal modeling and prediction.
The People Behind the Research
The research matters, but what really makes FCRC Track 2 special is the people. Every project is anchored by a student researcher, mentored jointly by IBM scientists and RPI faculty. This model creates a pipeline of talent that is deeply fluent in both hardware and software, theory and practice.
 The next generation of researchers? My son enjoyed exploring the poster session!
The next generation of researchers? My son enjoyed exploring the poster session!
I'm deeply grateful to my co-lead Professor Christopher Carothers from RPI, to all the IBM and RPI mentors, and most of all to the students whose curiosity and dedication make this work possible. The FCRC collaboration is proof that when industry and academia come together with a shared vision, the results can be extraordinary.
Looking Ahead: 2026 and Beyond
The work highlighted above represents our 2025 project outcomes. In 2026, Track 2 will continue this momentum with the same core focus on hardware-software co-design for scalable and efficient AI, while expanding into new directions shaped by where AI is actually headed.
On the digital accelerator side, we are placing special emphasis on emerging workloads such as agentic and interactive AI — systems optimized for the interactivity and dynamic behaviors typical of AI agents and copilots. As these workloads turn inference into a repeatedly-called subroutine, our research will target efficient inference of foundation and multi-modal models, inference-era model optimization through quantization, sparsity, and precision scaling, KV cache optimization, and inference server co-design for hardware-aware serving systems. We will also explore scalable distributed and heterogeneous execution across multi-node, multi-device setups using specialized accelerators like Spyre, including runtime systems and toolchains that enable efficient deployment and high utilization.
On the analog AI front, we will deepen our work on integrating analog compute elements into the digital system infrastructure — from hybrid architectures combining analog and digital accelerators via advanced packaging such as chiplets and 3D stacking, to robust analog inference algorithms that account for device non-idealities such as noise, variability, and drift. New directions include analog-aware model design with neural operators and activation functions tailored for analog substrates, cross-domain partitioning with compiler and runtime support for distributing workloads between analog and digital execution units, and end-to-end simulation frameworks for modeling and benchmarking foundation models on analog hardware at scale.
If you're interested in hardware-software co-design for AI, efficient LLM inference, or analog computing, I'd love to hear from you. Reach out via LinkedIn.
Discussion
Sign in with GitHub to leave a comment or react. Threads are public and live in this site's GitHub Discussions.