DeepSeek's Long March: V4, Sparse Attention, and What Open-Weight AI Just Taught Us
A hardware-aware reading of V4, DeepSeek Sparse Attention, and six lessons the open-weight world should be carrying forward. Companion to the IBM Mixture of Experts episode on V4, Decoupled DiLoCo, and IBM Granite 4.1 + Bob.
DeepSeek V4 [1] shipped on April 24, 2026, and most of the coverage went straight to the headline parameter count of 1.6 trillion parameters in total. The number that I keep thinking about is the second one: 49 billion parameters active per token, in a million-token context, with sparse attention doing the work that dense attention used to do.
The 1.6T number on its own would only describe a bigger model, while the 49B-active-per-token number is what makes a 1.6T model economically viable to actually run at inference time. Both numbers exist because a small Hangzhou lab spent 27 months grinding through architectural bets that, taken together, quietly rewrote the economics of open-weight frontier AI.
The 27-month arc, in six releases
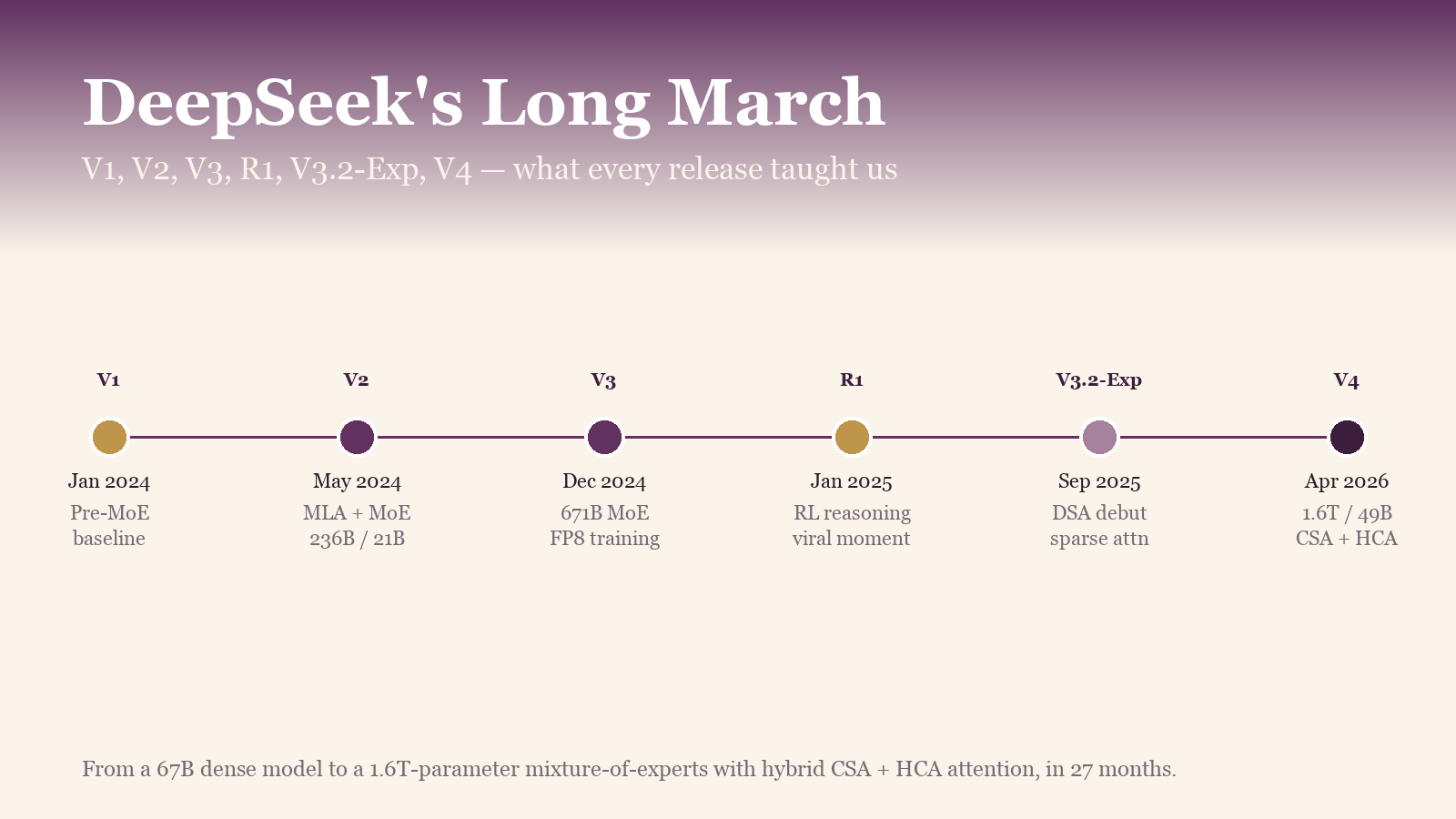
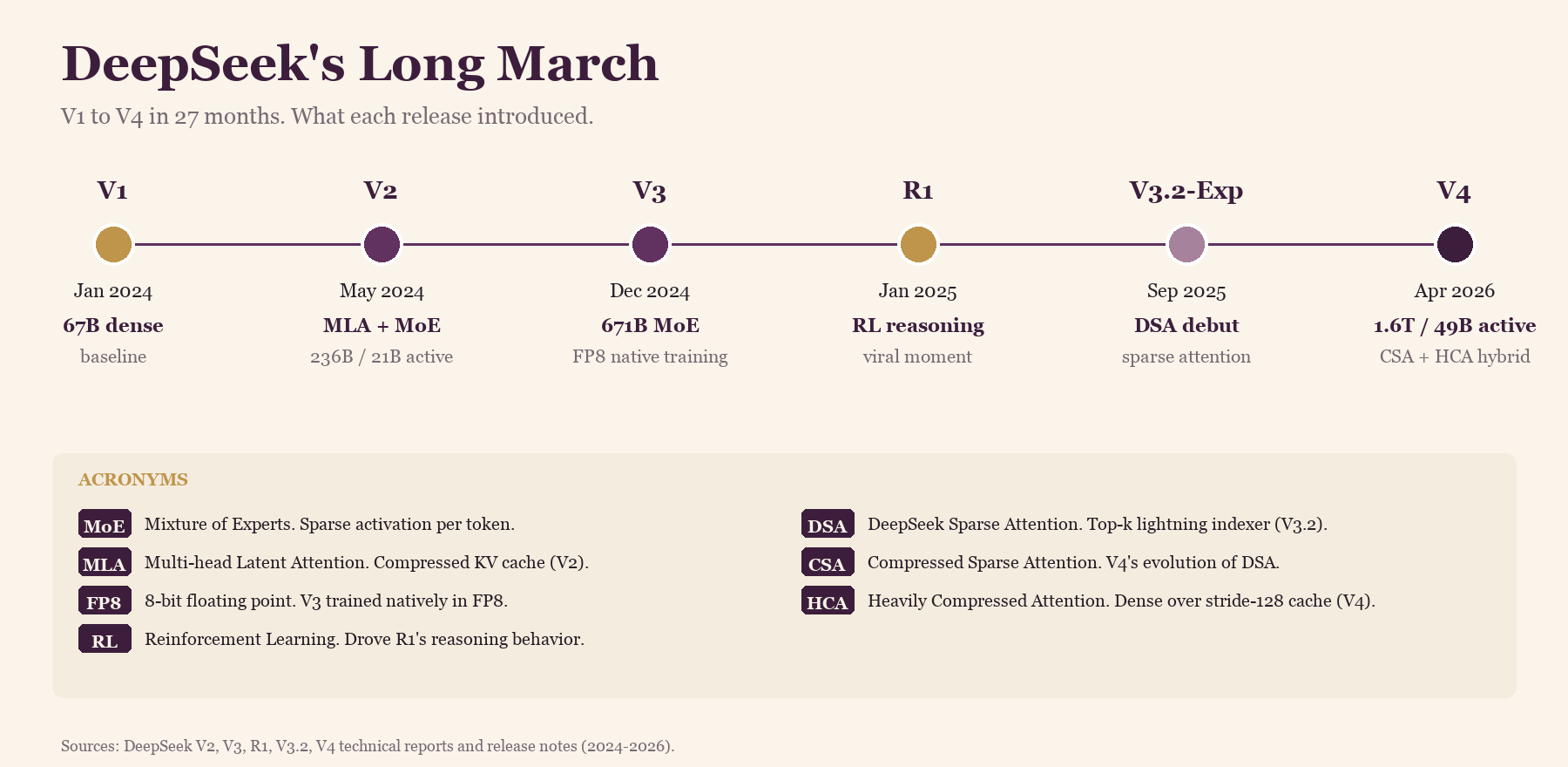 The arc traces a 27-month progression from a 67B dense baseline to a 1.6T-parameter mixture-of-experts model with sparse attention as the default path, where the architecture evolved at every release while the underlying optimization thesis stayed consistent throughout. An acronym key at the bottom of the figure provides a reference for the abbreviations used in the timeline and throughout the rest of the post.
The arc traces a 27-month progression from a 67B dense baseline to a 1.6T-parameter mixture-of-experts model with sparse attention as the default path, where the architecture evolved at every release while the underlying optimization thesis stayed consistent throughout. An acronym key at the bottom of the figure provides a reference for the abbreviations used in the timeline and throughout the rest of the post.
Each of the six releases pushed a different architectural idea, and the underlying strategy becomes clearer as the sequence progresses.
V1 (early 2024) was a 67B dense model with conventional architecture and no MoE. It was a useful first model but not architecturally differentiated from the rest of the field, and the team was primarily using it to build experience with the training and serving infrastructure.
V2 (May 2024) is where the architecture changed. DeepSeek-V2 introduced Multi-head Latent Attention (MLA) [2], which compresses the KV cache into a low-rank latent vector, and combined it with DeepSeekMoE, their sparse expert architecture. The important technical numbers from V2 were 236B total parameters with 21B active per token, a 128K context window, a 93.3% reduction in KV cache size, and 5.76x higher generation throughput compared to a dense 67B baseline. This is the point where the lab stopped optimizing for model size and started optimizing for inference cost.
V3 (December 2024) scaled the same approach to 671B total parameters with 37B active per token and pre-trained the entire forward and backward pass in FP8 from step zero [3]. The full training run took 2.788M H800 GPU-hours, which made V3 not the largest model in the world at the time but the most efficient frontier-scale training run anyone had published, and a direct counter to the "we need more H100s" story that dominated US AI conversation at the time.
R1 (January 2025) is when DeepSeek became widely known outside AI research. R1 [4] showed that reasoning capabilities could be incentivized through pure reinforcement learning without any labeled chain-of-thought data, and AIME 2024 pass@1 jumped from 15.6% to 71.0% as a result. Closed-API prices started dropping within weeks of the release, which made R1 function as a market event in addition to a model release.
V3.1 / V3.2-Exp (September 2025) introduced DeepSeek Sparse Attention (DSA) [5], the architectural change that cut the quadratic cost of long context down to roughly linear. V3.2-Exp was explicitly experimental, but the path to V4 was already obvious to anyone watching the arXiv feed.
V4 (April 24, 2026) [1] ships DSA as the production default, scales the MoE to 1.6T / 49B active, and makes 1M context the default tier across web, app, and API, available at the baseline pricing rather than as a premium add-on.
The six releases all serve the same underlying thesis, which is to make the parts of the model that are not doing work as small and as skippable as possible, and then scale the parts that remain.
Start with MLA, not DSA
Multi-head Latent Attention (MLA) [2] shipped with DeepSeek-V2 in May 2024, two years before V4. Every later DeepSeek model is built on top of it, DSA included. If you want to understand why DeepSeek's inference cost keeps dropping while other labs' inference cost stays the same, this is the architectural choice to look at first.
The problem MLA solves: in a standard transformer with Multi-Head Attention (MHA), every attention head stores its own K and V vector per token in the KV cache. A 70B-class model with 64 heads stores 128 cache entries per token. Run that out to 128K context and the cache is in the hundreds of gigabytes per serving session. An H100 with 80GB of HBM (high-bandwidth memory) can fit maybe one conversation, which is the reason MLA was necessary as an architectural change rather than a serving optimization.
Llama 3 partially addressed this with Grouped-Query Attention (GQA), where several query heads share a single K/V head. DeepSeek-V2 used a different approach. It compresses K and V together into a single low-rank latent vector per token, and reconstructs the per-head K and V on demand at attention time.
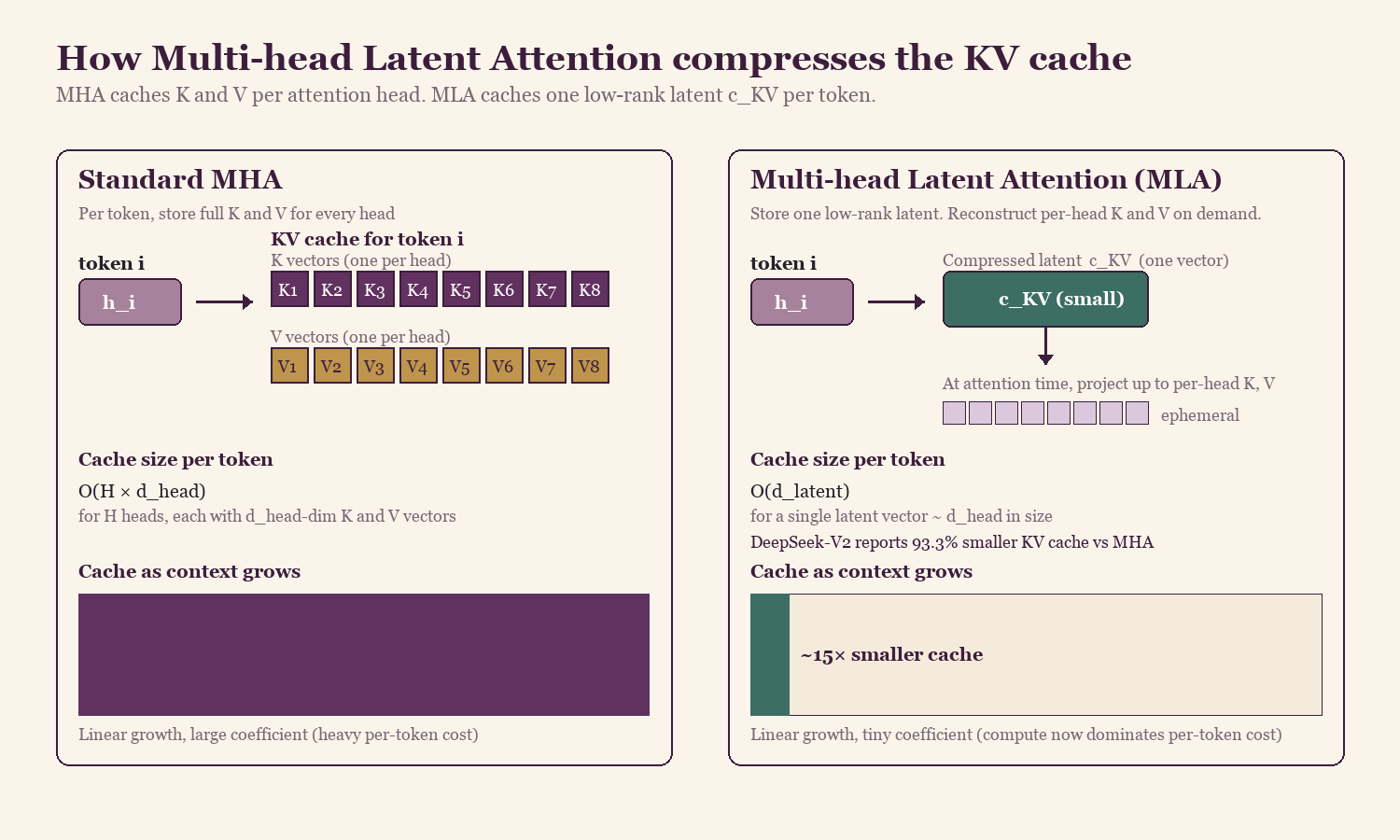 Standard MHA stores K and V for every head on every token. MLA stores one low-rank latent vector per token and reconstructs the per-head K and V when attention asks for them. DeepSeek-V2 reported a 93% reduction in KV cache size with no loss in capability.
Standard MHA stores K and V for every head on every token. MLA stores one low-rank latent vector per token and reconstructs the per-head K and V when attention asks for them. DeepSeek-V2 reported a 93% reduction in KV cache size with no loss in capability.
A few non-obvious things follow from this design choice.
1M context is economically viable because of MLA, not DSA. Pre-MLA, the KV cache at a million tokens would have been hundreds of gigabytes per serving session, while the post-MLA cache is roughly a fifteenth of that size. MLA is the foundation that makes everything else affordable at long context, and DSA only delivers its full benefit when it sits on top of an already-compressed cache.
DSA works because MLA already shrunk the cache. DSA in V3.2 and V4 runs directly on top of MLA in multi-query mode. The top-k selector operates over the latent representations, and the lightning indexer can run cheaply in FP8 specifically because the cache is already compressed and shared across query heads. Apply DSA to standard MHA instead, and the indexer has to re-rank every head independently; the kernel implementation becomes substantially harder to make efficient.
Adding MLA support is the hardest part of porting any DeepSeek model. Production MLA kernels in vLLM and SGLang landed over a substantial multi-release effort after V2 shipped rather than in a single drop, because MLA changes the memory layout, the projection geometry, and the math at the matmul boundary all at once.
In our own work porting MLA-class attention to the Spyre AIU, the friction point we ran into is that MLA's pattern of storing a compressed latent and projecting up to per-head K and V at attention time does not map cleanly onto the cache-and-attend kernel shapes that exist in most serving runtimes. The fused decompress-then-project step has to be a new primitive, with its own tiling decisions and its own numerics, and that one change ripples through the inference graph in several places at once: the memory layout for the latent cache, the way the indexer reads it in DSA mode, and the placement of the dequantize-and-project work relative to the softmax. MLA is where most of the kernel engineering goes when a team is bringing up a non-NVIDIA accelerator for these models.
FP8 native training, and why it is harder than it sounds
The other big V3 contribution gets less attention than it deserves: DeepSeek pre-trained the entire forward and backward pass of a 671B-parameter MoE in FP8, from step zero [3]. This is hard. FP8 formats (E4M3 and E5M2) expose extremely limited exponent and mantissa precision compared to BF16 or FP16, which makes the scaling strategy critical: any naive approach will under- or over-flow somewhere in the network, and the loss diverges.
Why fine-grained scaling fixes this: if your matrix has values from 0 to 1000 with a few outliers around 5000, a single per-matrix scale either saturates the outliers or rounds the small values to zero. Slice the matrix into small tiles, give each tile its own scale, and most tiles end up with a tight dynamic range that fits cleanly into FP8. The outlier tiles get their own larger scale and stay representable.
DeepSeek's specific approach: every 1×128 row of activations gets its own scale factor. Every 128×128 block of weights gets its own scale factor. The running sum stays in FP32 (32-bit) inside the CUDA cores at the matmul boundary so that precision is not lost during accumulation.
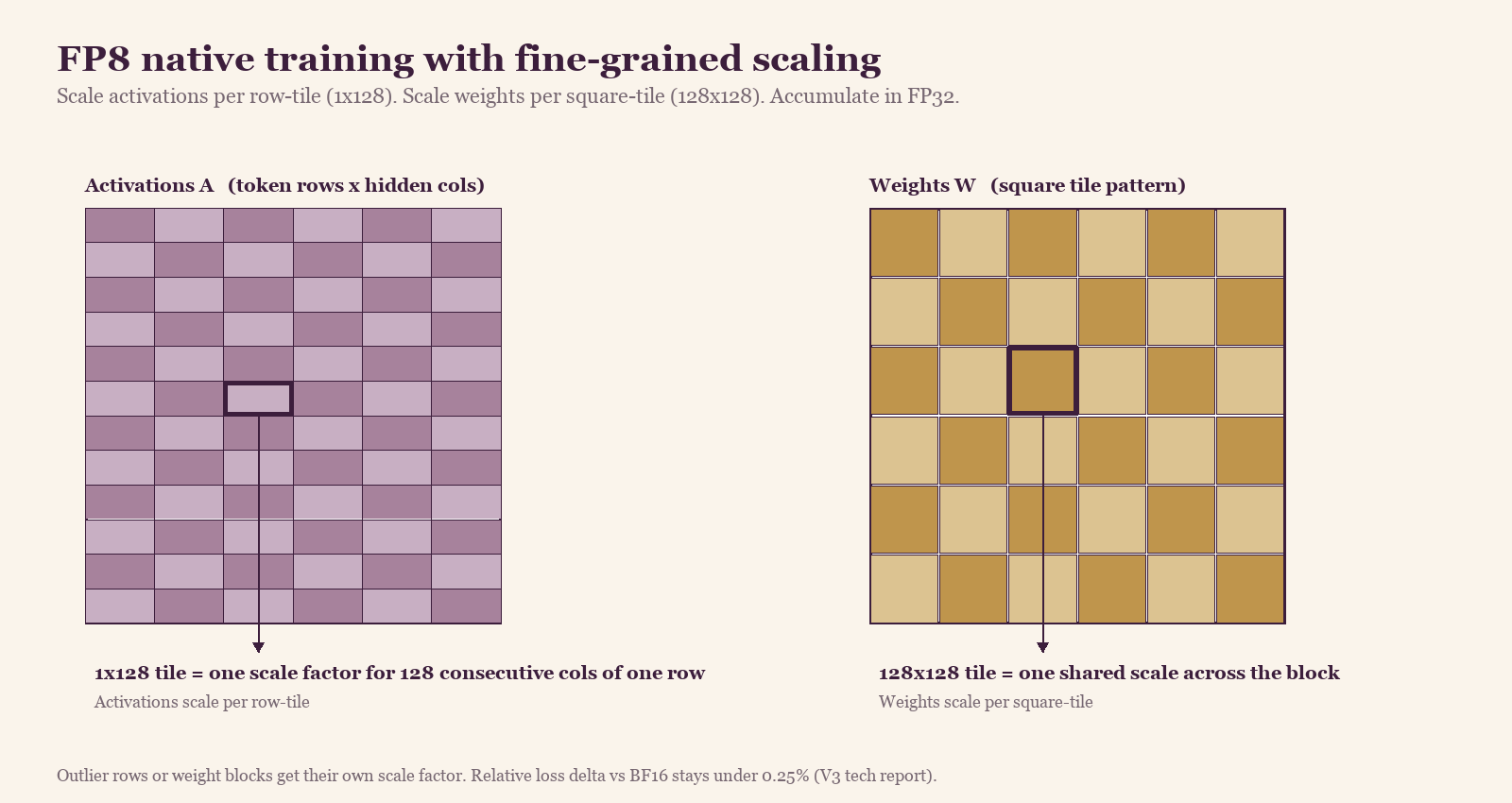 Activations scale per row-tile of 128 elements. Weights scale per 128×128 square tile. Accumulation runs in FP32 inside the CUDA cores. The relative loss delta versus a BF16 baseline stays under 0.25% across training.
Activations scale per row-tile of 128 elements. Weights scale per 128×128 square tile. Accumulation runs in FP32 inside the CUDA cores. The relative loss delta versus a BF16 baseline stays under 0.25% across training.
The end-to-end V3 training run took 2.788M H800 GPU-hours, roughly half of what comparable-capability dense models needed at the time. FP8 matrix multiplies run at roughly 2× the throughput of BF16 on Hopper tensor cores, and HBM traffic drops nearly proportionally. The savings were large enough that the lab could afford to run a frontier-scale training to completion under a budget that would otherwise have made the project infeasible.
Two more V3 innovations are worth knowing about, both of which carry into V4. Auxiliary-loss-free load balancing replaces the load-balancing loss most MoE papers still use with a bias-based routing strategy: cleaner training, no extra loss term competing with the main language modeling loss. And Multi-Token Prediction (MTP) trains the model to predict multiple future tokens per step. The same MTP heads double as a built-in speculative decoder at inference time. The model drafts several tokens ahead and verifies them in parallel, which is how V4 serves agentic coding workloads at the speed it does.
What DSA actually does, and why it is a hardware story
Sparse attention has a long history that includes Longformer, BigBird, and the sliding-window patterns used in Gemma 3 and Olmo 3. The DeepSeek contribution is not the underlying idea but rather two specific engineering choices that make DSA, to my knowledge, one of the first openly documented sparse-attention systems deployed as the default path at frontier scale.
The two-stage indexer. Standard attention computes a similarity score between each token and every other token. DSA replaces the expensive part with a fast scoring pass: a small indexer model running in FP8 computes a quick relevance score between the current token and every prior token. A top-k selector then picks the k=2,048 highest-scoring tokens. Expensive full attention runs only over those.
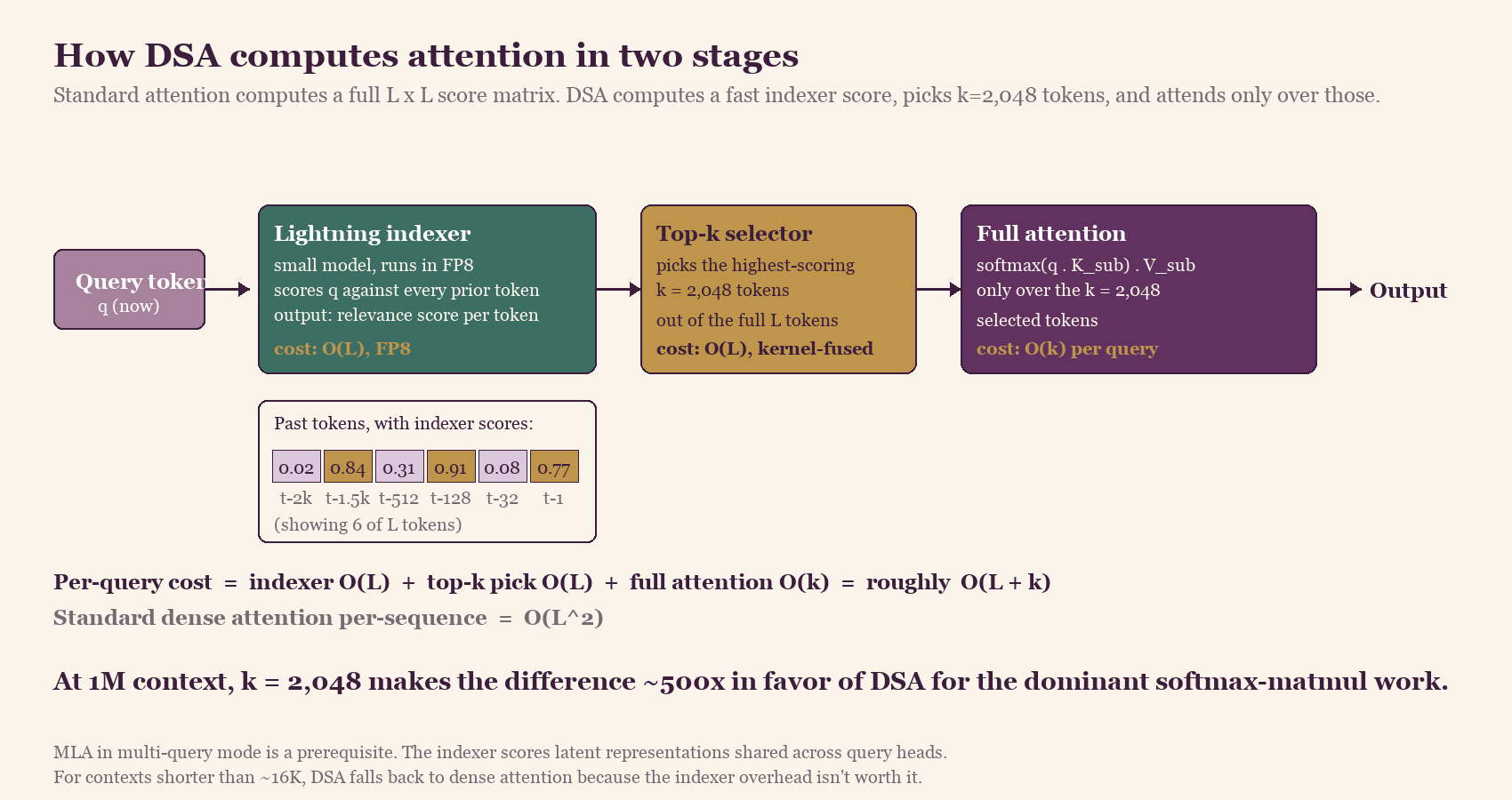 V3.2-class DSA: each query token goes through a cheap FP8 indexer that scores every prior token, a kernel-fused top-k step that picks the 2,048 most relevant ones, and full attention computed only over that subset. The dominant attention cost is reduced from quadratic to near-linear in the context length for fixed k. V4 extends this with an FP4 indexer and a CSA + HCA hybrid; see the next section for the V4-specific architecture.
V3.2-class DSA: each query token goes through a cheap FP8 indexer that scores every prior token, a kernel-fused top-k step that picks the 2,048 most relevant ones, and full attention computed only over that subset. The dominant attention cost is reduced from quadratic to near-linear in the context length for fixed k. V4 extends this with an FP4 indexer and a CSA + HCA hybrid; see the next section for the V4-specific architecture.
The complexity story is that standard attention is O(L²) in sequence length, while DSA reduces the dominant quadratic behavior by running the expensive softmax-and-matmul work over only ~2,048 tokens instead of all L. There is still O(L) work in the indexer pass and the top-k step, but those run in FP8 at much lower per-token cost, and the math works out to effectively near-linear scaling in practice for the configurations DeepSeek targets.
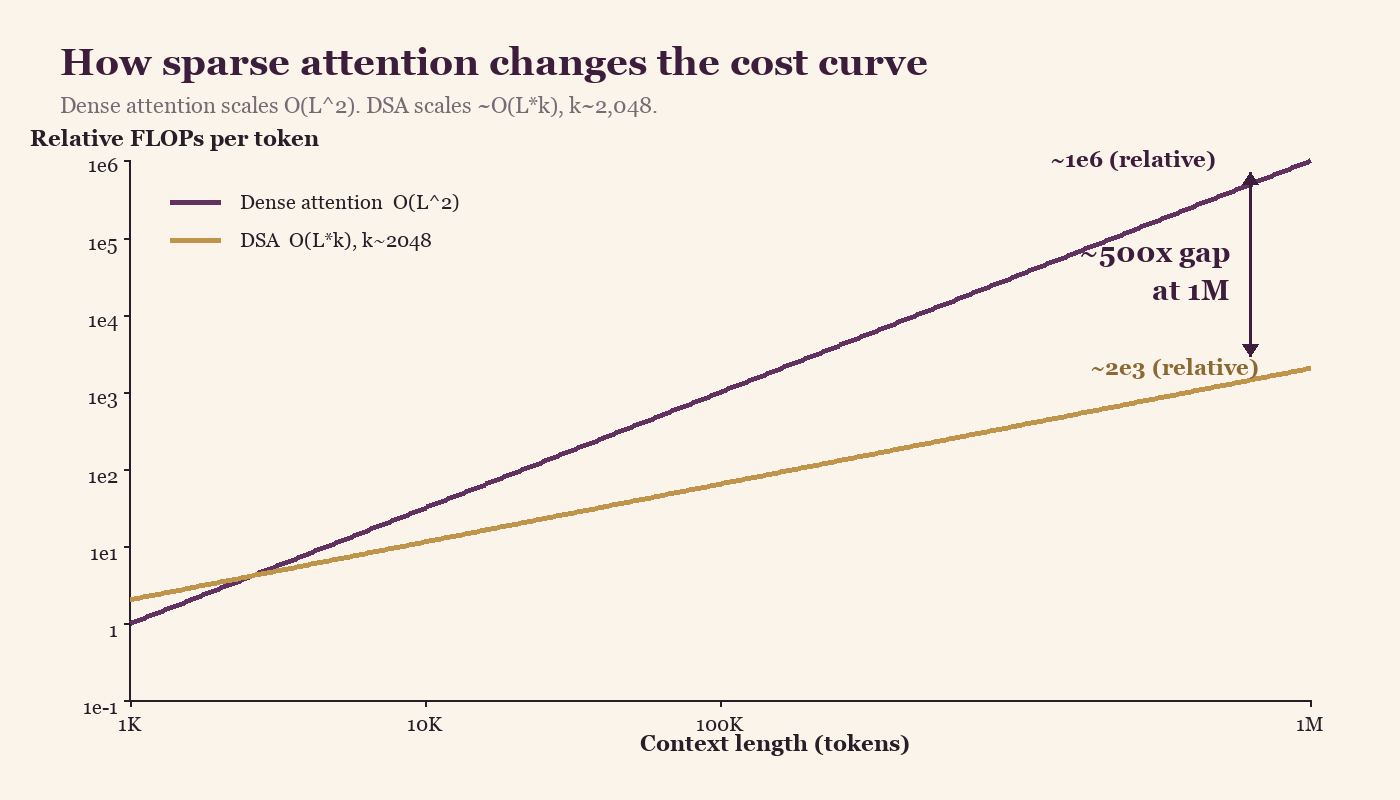 Relative FLOPs per token on a log-scale y-axis (each gridline is 10×). Dense attention scales quadratically with context length. DSA's dominant attention cost scales near-linearly because the expensive softmax-and-matmul work runs over a fixed k. At 1M context, the gap in the dominant term is roughly 500× in favor of DSA — note that the y-axis is logarithmic, so the visual gap is compressed relative to the actual ratio.
Relative FLOPs per token on a log-scale y-axis (each gridline is 10×). Dense attention scales quadratically with context length. DSA's dominant attention cost scales near-linearly because the expensive softmax-and-matmul work runs over a fixed k. At 1M context, the gap in the dominant term is roughly 500× in favor of DSA — note that the y-axis is logarithmic, so the visual gap is compressed relative to the actual ratio.
The hardware co-design. What most coverage misses is that DSA is not a software-only change that any serving stack can adopt. The indexer runs in FP8 because Hopper tensor cores expose an FP8 path. The variable per-query sparsity pattern requires custom CUDA kernels, because standard attention kernels cannot handle "different k tokens per query" efficiently. The whole design is built on top of MLA in multi-query mode so that the KV cache stays compressed across queries. For short contexts it falls back to dense attention because the indexer overhead is not worth paying below a threshold length.
That last detail matters more than it sounds. DSA uses sparse attention when sparse attention is faster and dense attention when it is not, and the switch happens inside a kernel that is designed for the accelerator's memory hierarchy. Retrofitting this behavior into vLLM or TensorRT-LLM requires substantial kernel-level changes to those runtimes, which is not impossible but is significantly more involved than flipping a configuration flag.
DSA shipped first in V3.2-Exp in September 2025, was hardened in V3.2 in December 2025, and continued to evolve through V4 in April 2026. The seven-month progression from experimental release to production default is the kind of cadence that comes from a team that treats kernel engineering as production work rather than as paper figures.
What V4 actually changed beyond V3.2's DSA
The description above is V3.2-class DSA, which is the foundation that V4 builds on. V4 went further than V3.2, and the official V4 technical report describes a hybrid attention scheme that interleaves two related mechanisms across the layers of the model. (A note on what is documented versus inferred: the mechanism descriptions below are taken from DeepSeek's V4 technical report. Some of the serving-stack implications I draw at the end of this section are my own reading of the architecture rather than something DeepSeek explicitly documented.)
Compressed Sparse Attention (CSA) is the direct descendant of V3.2's DSA, but the indexer now scores over already-compressed entries. A learned token-level compressor with stride 4 condenses every neighborhood of tokens into a single entry, and the lightning indexer picks roughly 128 of those compressed entries per query for the expensive softmax-and-matmul step. The indexer itself moved from FP8 in V3.2 down to FP4 (MXFP4) in V4, with FP4 quantization-aware training keeping accuracy stable. This represents another halving of bytes per indexer activation on top of everything DSA already did.
Heavily Compressed Attention (HCA) is more aggressive. It consolidates KV entries with stride 128 — at 1M context, that turns the cache from ~1M positions into roughly 8K compressed entries. The cache is small enough at that point that dense attention over the entire compressed stream is feasible again. HCA gives the model a holistic, low-resolution view of the full context that complements CSA's precise sparse retrieval over selected regions.
V4-Pro uses HCA for its first two layers and then alternates CSA and HCA through the rest of the model. V4-Flash starts with sliding-window attention before falling into the same CSA/HCA alternation. Different layers do different things: some get the precise sparse retrieval pattern of CSA, others get the holistic global view of HCA.
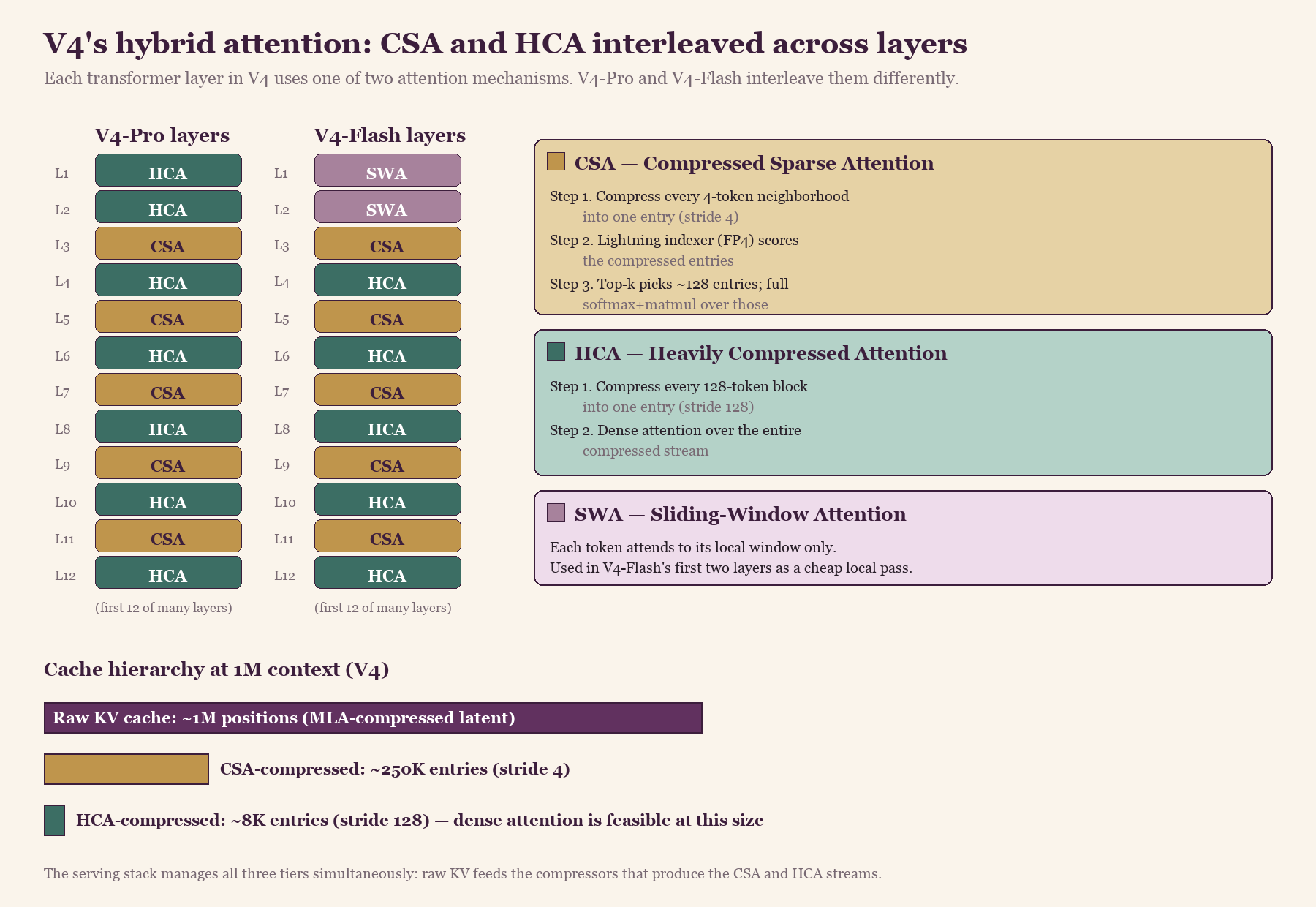 V4-Pro and V4-Flash both interleave Compressed Sparse Attention and Heavily Compressed Attention layer-by-layer. The serving stack manages three cache tiers simultaneously: raw KV at ~1M positions, CSA-compressed at ~250K entries (stride 4), and HCA-compressed at ~8K entries (stride 128).
V4-Pro and V4-Flash both interleave Compressed Sparse Attention and Heavily Compressed Attention layer-by-layer. The serving stack manages three cache tiers simultaneously: raw KV at ~1M positions, CSA-compressed at ~250K entries (stride 4), and HCA-compressed at ~8K entries (stride 128).
The practical consequence for anyone building inference infrastructure on top of V4: the cache is now multi-level. Raw KV entries, CSA-compressed entries, and HCA-compressed entries all coexist, and the serving stack has to manage three different staleness and precision tiers. The kernel surface area is meaningfully larger than V3.2's, and the FP4 indexer in particular needs hardware that handles MXFP4 efficiently — which currently means Blackwell or Hopper-class with software emulation.
Memory bandwidth is the common target
The four innovations cut cost on different axes, but the underlying point of all of them is the same. Modern LLM serving is increasingly memory-bandwidth-bound rather than compute-bound: generating a token spends most of its time streaming weights and KV state from HBM into the compute units, not doing math. Each architectural choice in V4 reduces bytes moved per generated token. MoE activates only a small fraction of the parameters, so fewer weights cross HBM. MLA compresses the KV cache by ~15×, so fewer cache bytes cross HBM per attention step. FP8 halves the bytes per tensor for both weights and activations. DSA cuts the number of KV entries that the expensive attention path actually touches. Fewer FLOPs is a side effect; reducing memory traffic is what each of them is really doing.
How the gains compound
Each of these innovations would be a respectable paper on its own. The reason V4 performs as well as it does is that they target different bottlenecks and compose. MoE acts on active compute. MLA acts on KV cache size and the memory bandwidth that pays for it. FP8 acts on bytes per tensor for both weights and activations. DSA acts on attention's scaling in context length.
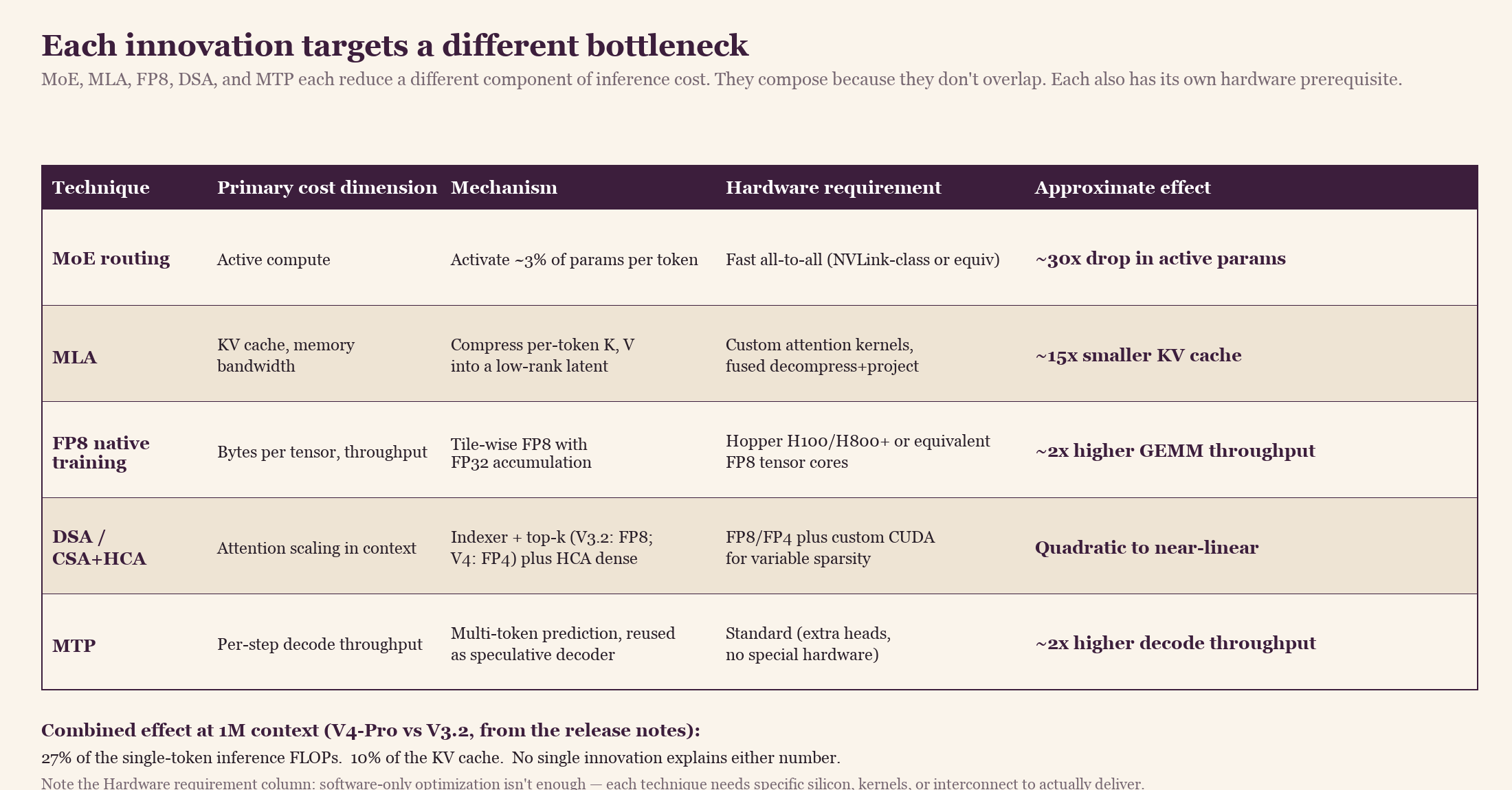 Each architectural choice cuts inference cost on a different axis, and they stack multiplicatively. The DSA column is the V4-Pro number at 1M context relative to V3.2, taken from the V4 release notes. Earlier columns indicate the rough magnitude of each contribution, not exact figures.
Each architectural choice cuts inference cost on a different axis, and they stack multiplicatively. The DSA column is the V4-Pro number at 1M context relative to V3.2, taken from the V4 release notes. Earlier columns indicate the rough magnitude of each contribution, not exact figures.
DeepSeek's V4 release notes state that V4-Pro needs 27% of the single-token inference FLOPs and 10% of the KV cache of V3.2 at 1M context. DSA alone is not 4× better than what came before, but the gain compounds because each earlier choice had already removed a layer of cost. MLA had already compressed the cache, MoE had already gated 97% of the parameters off, and FP8 had already halved the bytes per tensor. DSA on top of all of that then turns the remaining quadratic context cost linear. Each layer of the stack depends on the one below it, and removing any single layer would cause the savings to disappear.
The economics of sparse activation
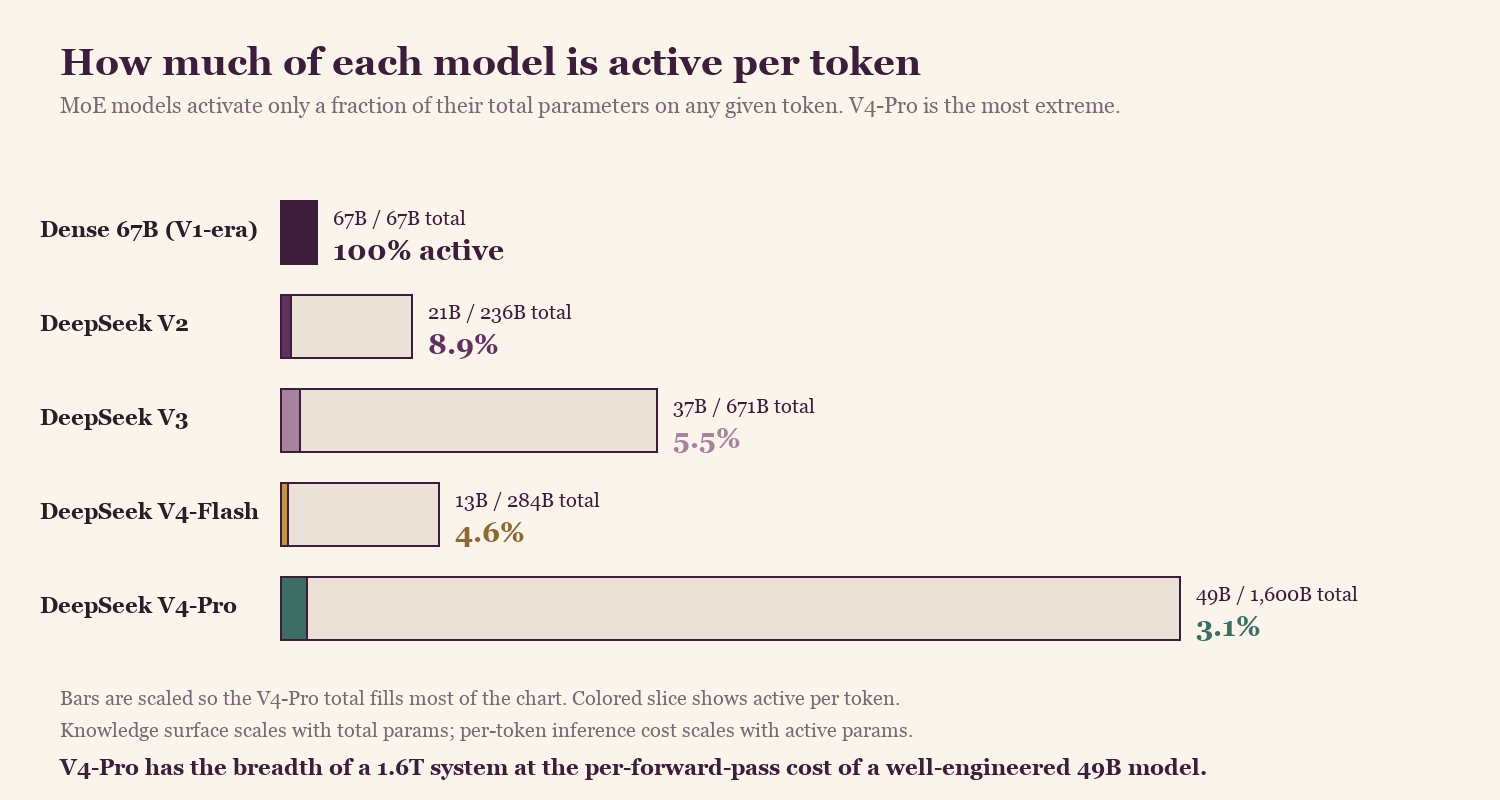 V4-Pro activates roughly 3% of its parameters per token. The model knows what a 1.6 trillion-parameter system knows; the inference cost is closer to a 49B model.
V4-Pro activates roughly 3% of its parameters per token. The model knows what a 1.6 trillion-parameter system knows; the inference cost is closer to a 49B model.
When people ask me whether closed labs can match this, my answer keeps coming back to the same number. V4-Pro activates 49 billion parameters out of 1.6 trillion per token, which is roughly 3% of the model, and that ratio is what determines the inference economics. The model retains the capability of a 1.6T system while running at roughly the inference cost of a well-engineered 49B dense model.
This is the structural reason DeepSeek's aggressive sparsity strategy puts downward pressure on closed-API pricing. Closed labs likely run their own sparsity and MoE optimizations internally, but the available open weights at comparable capability put a hard floor under what any commodity-tier API can charge. The 2026 Stanford HAI AI Index documents the pattern: every time DeepSeek ships a competitive open model, closed-API prices drop within weeks [6].
The gap between hype and reality
The coverage on V4 says "everyone is switching to DeepSeek." The reality is more layered.
V4-Pro at 1.6T parameters is too large for most enterprises to self-host. It needs a multi-GPU cluster, minimum 4 to 8 H100s. Real deployment splits across three tiers, and the flagship is a smaller part of the picture than the coverage suggests:
- Hyperscaler-managed. AWS Bedrock, Azure AI Foundry, and Google Vertex AI all host DeepSeek's earlier models. None have announced V4-Pro hosting at the time of writing (the model has been live for five days). Real adoption numbers are not disclosed.
- Specialized inference providers. Together.ai, Fireworks, OpenRouter, Replicate. This appears to be where most non-Chinese DeepSeek usage happens in practice, through OpenAI-compatible APIs.
- Distilled and self-hosted variants. DeepSeek-R1-Distill-Llama-70B has likely become the practical default for local reasoning workloads, with the Qwen-32B distill close behind for smaller hardware footprints. This is what US enterprises typically deploy when they want the capability but do not want to send data to DeepSeek's API directly.
The most concrete V4 enterprise integration so far is Aurora Mobile (NASDAQ: JG), which integrated V4 Preview into its GPTBots.ai platform on launch day for enterprise RAG over CRM/ERP data. The integration is significant as the first day-one V4 deployment by a US-listed company, though a single integration of this kind demonstrates feasibility rather than broad enterprise adoption.
The honest summary: V4-Pro is more of a capability demonstration than a production model. The real adoption story is V4-Flash (284B / 13B active), which is self-hostable on a multi-GPU setup most mid-size teams can afford, and the distilled variants that fit on a single high-end server. The flagship gets the coverage; the second-tier model gets deployed.
Six lessons worth carrying forward
The arc from V1 to V4 contains specific lessons that I think generalize beyond DeepSeek, and that I find myself coming back to whenever I talk to my Columbia students or when I think about what the Spyre accelerator stack at IBM should optimize for next.
1. MoE made parameters cheap, and sparse attention is now making context cheap
These are the same trick applied at different layers of the model. MoE proposes that the parameter count be scaled while only a small fraction of parameters is activated per token, and DSA proposes that the context length be scaled while only a small fraction of tokens is attended to per query. Both approaches turn a quadratic-or-worse cost into something roughly linear, and both require the hardware to actually skip the inactive part, because sparsity that the silicon cannot exploit is only a math claim rather than a real speedup.
The next opportunity after these two will be the same underlying idea applied to a different dimension. Activation sparsity within feed-forward layers (Deja Vu, contextual sparsity) is one candidate, and KV cache eviction along the sequence dimension (H2O, SnapKV) is another. The pattern is clear: find a dimension that is dense in the model and sparse in reality, then design a kernel that takes advantage of the gap.
2. Hardware co-design beats pure algorithmic cleverness, every time.
DSA could have been "we ran a top-k selection in PyTorch and it works in principle." That version of the work probably gets accepted at a conference, but it does not get shipped as the production default at frontier scale.
What DeepSeek did instead is to make every design choice hardware-aware: an FP8 indexer because the tensor cores have an FP8 path, custom CUDA kernels for variable per-query sparsity because the existing kernels cannot handle it, MLA in multi-query mode so that KV cache compression compounds with attention sparsity, and a dense fallback for short contexts because the indexer overhead does not pay below a threshold. Every choice is hardware-aware.
For those of us working on accelerator stacks (on the IBM side, that is the work my group does day to day with torch-spyre and the Spyre AIU), this is the right reference architecture to study. Pure-software optimization on top of a generic accelerator does not get you there, and the hardware path has to be designed around the same sparsity pattern that the algorithm relies on.
3. Open weights with permissive licensing won the commoditization race.
The commoditization shift has already played out in pricing data. Every time DeepSeek (or Qwen, or Mistral, or now Zhipu's GLM-5) ships a competitive open model, closed-API prices drop within weeks, and Stanford HAI has been documenting this pattern in the AI Index for three consecutive years [6].
The "can open labs survive against closed frontier labs" question is the wrong one to be asking now. Open labs have already won on commoditization. Closed labs can no longer charge premium prices on the basic API tier.
4. Vertical specialization is what comes next.
We are past the era where every open lab tries to train a general-purpose frontier model. Each lab now specializes:
- DeepSeek leads on the sparse-attention architecture story and frontier-scale efficiency.
- Alibaba Qwen 3.6 Plus is marketed primarily for agentic coding and reasoning, with the strong multilingual support the Qwen line has always had as a secondary axis.
- Mistral Small 4 focuses on European, GDPR-friendly, edge-deployable models.
- Zhipu's GLM-5 is reportedly trained at large scale on Huawei Ascend infrastructure, demonstrating the growing feasibility of non-NVIDIA training stacks for frontier models.
- Google's Gemma 4 targets mobile and edge devices — a tighter hardware envelope than laptops.
- IBM's Granite 4.1 focuses on enterprise governance, a modular family, and calibrated uncertainty.
Open-weight AI is not dying. It is segmenting into a set of labs that each own one or two capability axes, which is a healthier outcome than the all-or-nothing race that dominated 2024.
5. The hype gap is also the deployment gap.
V4-Pro is more of a capability demonstration than a production model, while V4-Flash is what most teams actually deploy and the distilled variants are what US enterprises tend to run in-house. This pattern of a flagship that sets the ceiling and a second-tier model that absorbs the deployment volume repeats across labs and across release cycles.
The implication for anyone doing enterprise architecture: plan for the second-tier model, not the flagship. The flagship sets the capability ceiling and the marketing tone. The second-tier model, typically the 200–400B MoE with 13–25B active, is what ends up in production. The same pattern appears to hold for closed-API stacks, where the cheaper variant likely handles the large majority of traffic.
6. Hardware decoupling from NVIDIA is real.
Reporting around V4 suggests DeepSeek had to re-adapt the model to Chinese-made chips, which delayed the release by months. Reports around Zhipu's GLM-5 and other Chinese frontier models suggest that large-scale training on non-NVIDIA accelerator stacks is becoming increasingly viable — particularly Huawei's Ascend line, which SemiAnalysis has covered in depth [7]. Export restrictions are accelerating investment in alternative hardware ecosystems, and the trend is unlikely to reverse.
The work involved is not just kernel re-adaptation. The real friction sits at the interconnect layer. NVIDIA's stack assumes NVLink and NVSwitch between accelerators on the same node and within a rack, giving you fat, low-latency all-reduce and all-to-all primitives that MoE routing and KV-cache sharding take for granted. Huawei's Ascend uses its own HCCS interconnect with the HCCL collective library; PCIe-based alternatives have lower per-link bandwidth and different topology. Porting a DeepSeek-class model to a non-NVIDIA fabric means rewriting the expert-routing path, the sharding strategy for the KV cache, and often the pipeline-parallel schedule, in addition to the kernels. The interconnect is where most of the hardest engineering ends up.
That is still good news for everyone who is not NVIDIA. A monoculture where every stack optimizes for one vendor's specific design choices produces fragile software. With DeepSeek's architecture now running on multiple hardware substrates, and the broader push toward non-NVIDIA training accelerators gaining traction, the design space opens up for every accelerator group working on frontier-scale workloads, including the work my group does at IBM Research on Spyre.
What changes because of 1M context as the default
One specific implication deserves attention because it changes a design decision that has been considered settled in enterprise architecture for three years.
When DeepSeek makes 1M context the default tier, every enterprise that built a RAG pipeline in the last two years has to revisit a question they thought was answered. RAG won three years ago because context was expensive. Quadratic attention meant doubling context quadrupled cost; putting 500K tokens into a prompt was financially impractical. So everyone built retrieval pipelines: chunk the knowledge base, embed it, search for the relevant chunks, send only those into a small context window.
DSA changes that economics. The expensive softmax-and-matmul step runs over a fixed ~2,000 tokens regardless of context length. The lightning indexer still scans every prior token, but it runs in low precision at a tiny per-token cost. The total per-query work goes from O(L²) to roughly O(L + k), where the dominant term is no longer the softmax. There are now three options where there used to be one:
- Pure RAG. Keep retrieving small chunks. Cheap and fast, but fragile. If retrieval misses the relevant chunk, the model never sees the answer and confidently makes one up.
- Pure long context. Send everything into the prompt. Simple and reliable. The cost is the catch: you pay for ~1M tokens per query, which adds up at scale.
- Wide-net hybrid. Use retrieval to fetch a much larger window of plausibly relevant material (say, 100K tokens instead of 4K), then let long context handle precision. Most production systems will end up here.
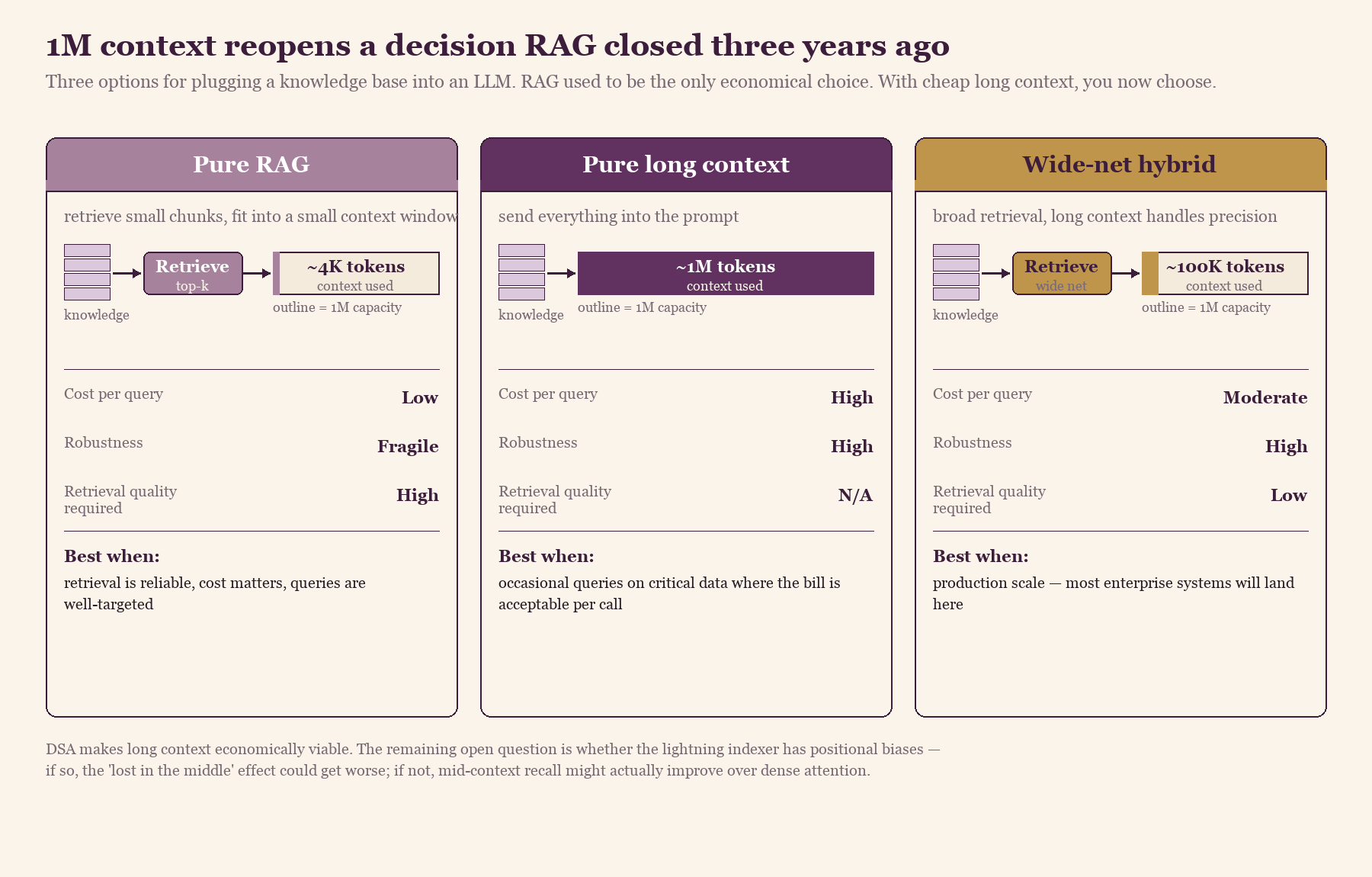 Each card uses the same context-capacity outline (representing 1M tokens). The colored fill shows how much of that capacity each strategy actually consumes per query. Pure RAG pays for almost nothing per query but depends on retrieval precision; pure long context is the inverse; the wide-net hybrid is where most production systems will settle.
Each card uses the same context-capacity outline (representing 1M tokens). The colored fill shows how much of that capacity each strategy actually consumes per query. Pure RAG pays for almost nothing per query but depends on retrieval precision; pure long context is the inverse; the wide-net hybrid is where most production systems will settle.
The architectural shift is not huge, but it is real. The optimization target moves from retrieval precision toward selecting what to include in the much larger window, which is a different problem that calls for a different set of tools.
One open question is worth flagging here as well. Dense long-context models exhibit the "lost in the middle" effect (Liu et al., 2023): recall is strong for tokens near the beginning and end of the prompt and weaker for tokens buried in the middle. With DSA, the recall behavior in the middle of a 1M-token prompt depends on whether the lightning indexer reliably picks the right ~2,048 tokens. If the indexer is well-calibrated across positions, DSA might actually improve mid-context recall over dense attention by focusing the expensive computation where it matters. If the indexer has positional biases, the lost-in-the-middle effect could get worse instead of better. We do not yet have public evals at 1M context that clearly answer this question, and it is the one I would most want a DeepSeek engineer to publish a needle-in-a-haystack-style report on.
From the hardware side, which is where my attention sits, the main bottleneck shifts to a different set of components. The main cost under DSA is no longer attention compute itself but rather the lightning indexer running in FP8, the top-k selection at scale, and the KV cache management for million-token sequences. Memory bandwidth, KV cache eviction policies, and the pipelining of the indexer's outputs become the new bottlenecks, and anyone optimizing serving infrastructure for the old "short context, expensive attention" model is solving the wrong problem.
What this means for accelerator design
For anyone designing or evaluating an AI accelerator in 2026, the V4 architecture is a useful stress test. A chip that is optimized for the previous generation's workload of dense GEMMs over big tensors, long contiguous reads from HBM, and regular access patterns will struggle with the V4 hot paths. The performance-critical kernels for a DSA-style stack live somewhere else entirely.
A few of the new pressure points worth designing for:
- KV cache hierarchy. With MLA, the cache is small enough that more of it can live in higher levels of the memory hierarchy (HBM today, on-package SRAM tomorrow). The accelerators that win on long-context inference will be the ones that can keep more of the working KV state closer to compute.
- Sparse gather/scatter. Once top-k picks 2,048 tokens out of a million, the actual attention step needs to pull K and V vectors from non-contiguous positions in the cache. Standard contiguous-read DMA engines do not handle this access pattern well, so the design either copies the selected entries to a contiguous staging area first or relies on a gather-capable load unit.
- Top-k as a first-class operation. A fast top-k over a long sequence dimension is non-trivial. Accelerators with hardware sort or median-selection primitives have a real advantage here; everyone else implements it as a stack of bitonic sorts or approximate top-k.
- FP8 accumulation. Hopper's design choice — FP8 inputs, FP32 accumulation in the matmul — is now a baseline expectation. Accelerators that can only accumulate in BF16 either have to restructure the math or accept measurable precision loss in long training runs.
- Compiler and runtime work. The decompress-then-project step in MLA, the fused indexer-plus-top-k in DSA, and the variable per-query sparsity pattern do not slot into the abstractions that PyTorch's compiler stack was built around. Backend compiler and runtime teams end up writing new primitives and arguing with their schedulers about how to place them.
The systems thesis underneath all of this is that skipping work has become a first-class architectural goal rather than a clever optimization layered on top of dense compute. The accelerator stacks that internalize this design principle will keep up with the workload, and the stacks that do not will spend the next two years catching up.
Where the cost actually goes
Parameter count gets the coverage, but activation pattern is what determines what the model actually costs to run, and it is what decides whether a frontier model is economically viable at all. V4 is the clearest current example, with a 1.6 trillion-parameter model that serves at roughly the cost of a well-engineered 49B dense model and with attention costs that scale far more gently than dense attention at long context. Every layer of the stack is engineered around skipping what does not matter.
The labs that absorb this lesson are the ones that keep shipping at competitive cost, while the labs that do not continue to train bigger dense models and watch their inference margins disappear.
References
[1] DeepSeek-AI, "DeepSeek V4 Preview Release," DeepSeek API news, April 24, 2026.
[2] DeepSeek-AI, "DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model," arXiv:2405.04434, May 2024.
[3] DeepSeek-AI, "DeepSeek-V3 Technical Report," arXiv:2412.19437, December 2024.
[4] DeepSeek-AI, "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning," arXiv:2501.12948, January 2025.
[5] DeepSeek-AI, "DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models," arXiv:2512.02556, December 2025 (introduces DeepSeek Sparse Attention).
[6] Stanford HAI, "The 2026 AI Index Report," Stanford Institute for Human-Centered AI, 2026.
[7] SemiAnalysis, "Huawei AI CloudMatrix 384 — China's Answer to NVIDIA GB200 NVL72," 2025. (Industry analysis of Huawei's Ascend training cluster strategy and its position relative to NVIDIA rack-scale systems.)
Discussion
Sign in with GitHub to leave a comment or react. Threads are public and live in this site's GitHub Discussions.