AI at the Inflection Point: Economics, Discovery, and the End of Passive Cybersecurity

The week of April 7, 2026 surfaced three stories that, read together, reveal something larger than any single headline: frontier AI is simultaneously becoming a capital infrastructure business, a nascent scientific partner, and a weapons-grade security threat. I discussed all three topics on this week's IBM Mixture of Experts podcast with Tim Hwang and Martin Keen. This post goes deeper into each.
The Economics of Frontier AI: From Software Business to Capital Infrastructure
The Wall Street Journal obtained confidential financial documents from OpenAI and Anthropic. The numbers reveal two very different bets on how to survive.
This week the Wall Street Journal published confidential financial documents from both OpenAI and Anthropic [1], materials shared with investors ahead of their latest funding rounds and anticipated IPOs. Most coverage fixated on the revenue horse race. That misses the more important story: these financials reveal two fundamentally different architectural bets on the future of AI.
| Metric | Value | Detail |
|---|---|---|
| $30B | Anthropic ARR | Anthropic annualized revenue run rate, April 2026. Up from $1B in January 2025 — 30x in 15 months. |
| $24B | OpenAI ARR | OpenAI annualized revenue run rate, April 2026. Up from $2B ARR in 2023. |
| $121B | OpenAI compute | OpenAI projected compute spend in a single year (2028). Losses that year: ~$85B. |
| $30B | Anthropic training | Anthropic projected training cost for the same 2028 period — roughly 4x less than OpenAI. |
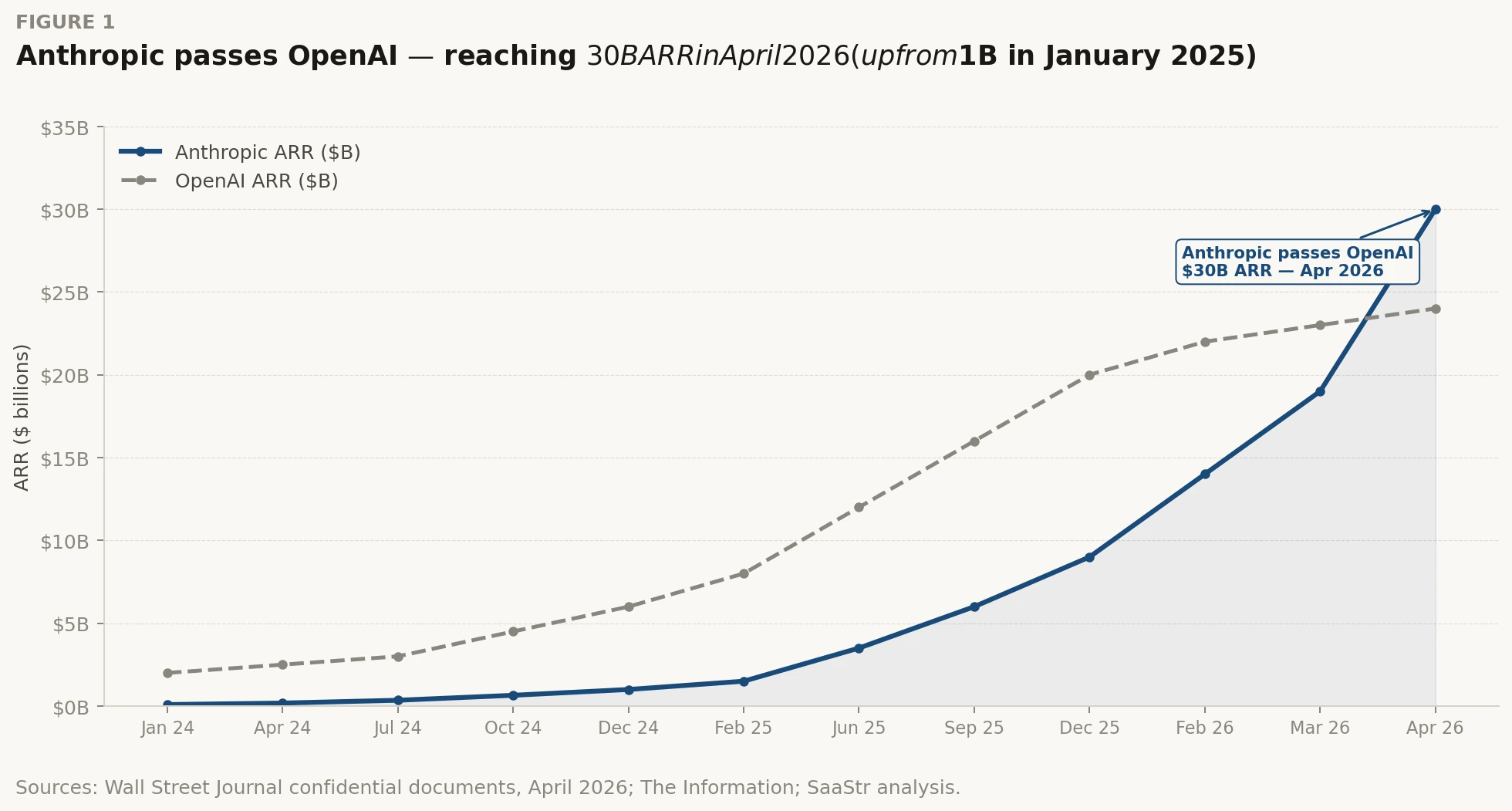 Sources: Wall Street Journal confidential documents, April 2026; The Information; SaaStr analysis. ARR calculated as last 4-week API revenue x 13 plus monthly subscriptions x 12.
Sources: Wall Street Journal confidential documents, April 2026; The Information; SaaStr analysis. ARR calculated as last 4-week API revenue x 13 plus monthly subscriptions x 12.
Anthropic passing OpenAI on run-rate revenue is remarkable [2]. Salesforce took 20 years to reach $30 billion in annual revenue. Anthropic did it in under three years from a standing start. And the jump from $9B to $30B happened in roughly eight weeks [3]. These are not normal software growth numbers.
But the structural number is not revenue. It is the compute cost divergence. Both companies are spending more than half of revenue on inference alone, before a single dollar of training cost is counted [1]. OpenAI projects $121 billion in compute spend in 2028, with losses that year approaching $85 billion. Anthropic projects roughly $30 billion in training costs for the same period, and expects to reach profitability in 2028 or 2029 [1][13]. OpenAI has pushed its breakeven target past 2030.
"These are not tech company financials. They are the economics of an arms race dressed in a spreadsheet."
The Full-Stack Cost Problem
Most commentary reduces "compute cost" to GPU spending. That is wrong. At the systems level, the cost structure of a frontier AI company spans the entire hardware-software stack, and the bottlenecks are not always where you expect them.
| Cost Category | Primary Driver | Economic Behavior | Hidden Bottleneck |
|---|---|---|---|
| Training compute | GPU/TPU clusters, FLOP budget | High, episodic (CAPEX-like) | Interconnect bandwidth, not raw FLOP |
| Inference compute | Serving requests at scale | Continuous, scales with adoption | Memory bandwidth — KV-cache dominates |
| Data movement | HBM bandwidth, NVLink, InfiniBand | Often larger than arithmetic cost | The real "compute" bottleneck at scale |
| Energy & cooling | Cluster power draw, PUE | Scales with cluster size, rising fast | Grid capacity — now a deployment constraint |
| R&D talent | Researchers, engineers | Secondary vs. compute | Concentration risk (few frontier teams) |
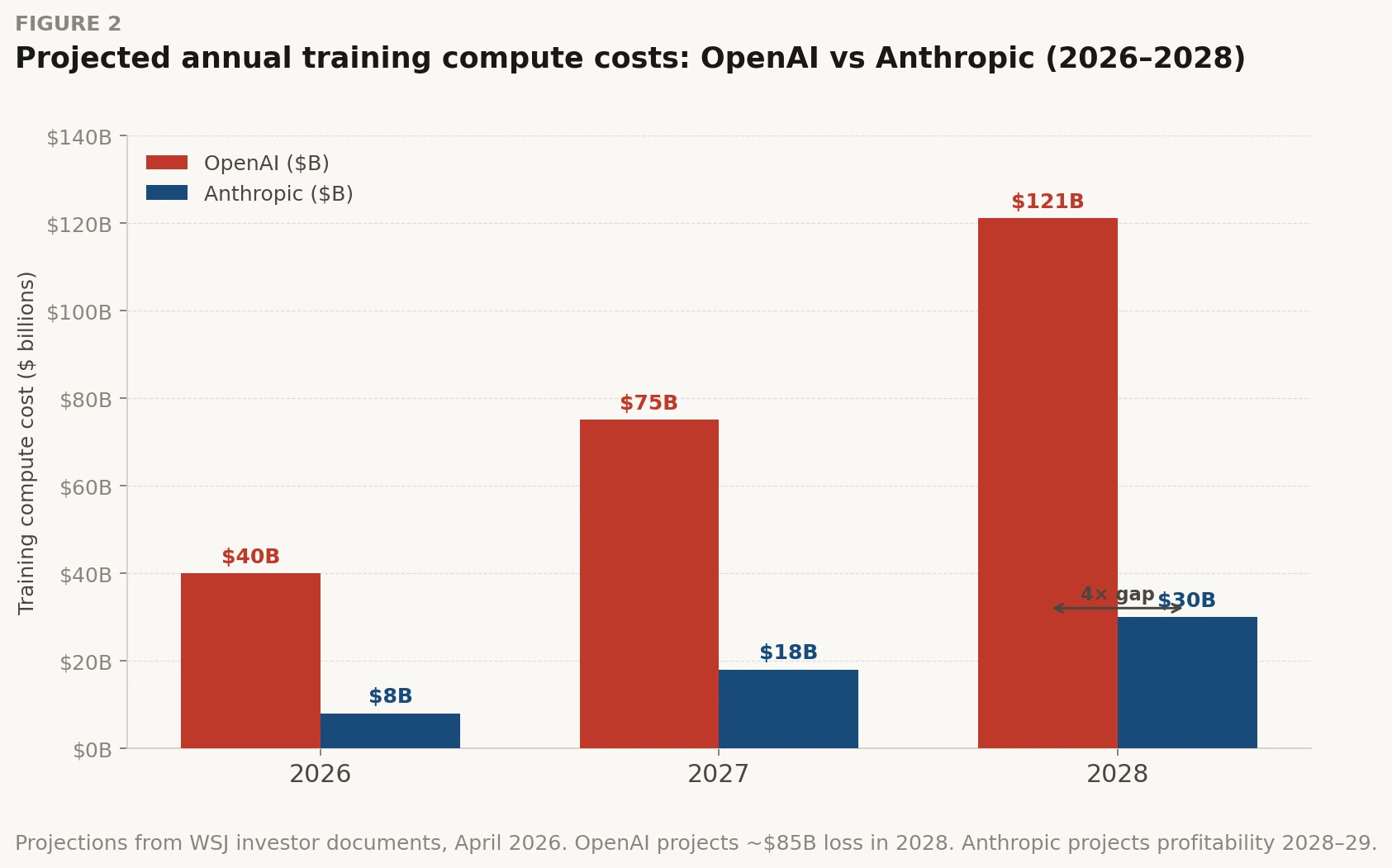 Projections from WSJ documents and investor materials. OpenAI 2028 figure represents compute costs in a single year with ~$85B projected loss. Anthropic projects breakeven in 2028–2029.
Projections from WSJ documents and investor materials. OpenAI 2028 figure represents compute costs in a single year with ~$85B projected loss. Anthropic projects breakeven in 2028–2029.
Enterprise vs. Consumer: The Real Strategic Divide
Anthropic never had a consumer phase. From the beginning, it built for enterprise API contracts and cloud provider deals [3]. The results: 80% of Anthropic's revenue comes from business customers. Eight of the Fortune 10 are Claude customers. Over 500 companies spend more than $1 million annually with Anthropic [2].
OpenAI has 900 million+ weekly active ChatGPT users. Anthropic has roughly 5% of that consumer reach. But Anthropic just passed OpenAI on top-line run-rate anyway. Consumer scale and revenue scale are different things. Enterprise contracts carry higher retention and better expansion economics. The company that was enterprise-first from day one is pulling ahead as a result.
Strategic Divergence at a Glance
| Dimension | OpenAI | Anthropic |
|---|---|---|
| Revenue composition | ~60% consumer (ChatGPT subscriptions), ~40% enterprise API — converging toward parity by end 2026 | ~80% enterprise API, ~20% Claude.ai Pro. Enterprise-native from inception; 8 of the Fortune 10 are customers. |
| Training cost strategy | Scale-first: $121B projected 2028 spend. Betting frontier capability is winner-take-all. | Efficiency-first: $30B projected 2028 spend. Same frontier race at 4x lower training cost — so far. |
| Profitability timeline | Breakeven pushed beyond 2030. ~$14B loss projected for 2026 before training costs. | FCF positive projected 2027–2028 including training costs. Structural cost advantage so far. |
| Cloud revenue accounting | Microsoft is "principal" on Azure OpenAI — cloud channel revenue not counted in OpenAI's ARR. | Considers itself "principal" in Google Cloud + AWS deals — all channel revenue counted in ARR. |
My take, systems perspective
What these financials actually show is that frontier AI has broken the SaaS economics model. In software, marginal cost of serving another user approaches zero as scale grows. In AI, the opposite is true: inference cost grows proportionally with adoption. Every new user is another burden on the datacenter.
So the real battle is not about model quality. It is about cost per token at inference time. Whoever solves hardware-software co-design for inference (memory efficiency, operator fusion, dataflow architectures that eliminate redundant data movement) will define the unit economics of this industry. Training gets the headlines. Inference wins the business.
Anthropic's 4x training cost advantage is striking but probably won't persist as the models it needs to compete get larger. The more durable advantage is enterprise monetization: those 500+ $1M+ annual contracts are not going anywhere, and they generate the data flywheel needed to improve models faster without proportional compute spend.
GPT-1900 and the Hard Problem of AI Scientific Discovery
A model trained exclusively on pre-1900 text tries to rediscover modern physics. What it reveals about the gap between pattern recognition and genuine theory creation.
GPT-1900 is an experimental language model trained exclusively on text published before the year 1900: books, newspapers, and scholarship from the nineteenth century and earlier [6]. It knows nothing about relativity, quantum mechanics, or the Standard Model. Researchers gave it the same observational anomalies and experimental data that confronted physicists at the turn of the twentieth century, and asked: can it rediscover what took Einstein, Planck, and Bohr a generation to produce?
Simple experiment. Deep implications. It forces a clean separation between two things often conflated in AI discourse: synthesizing existing knowledge and generating genuinely new theories.
"The question is not whether AI can do science. It already accelerates science. The question is whether it can break science — shatter a paradigm and build a new one from the ruins."
Paradigm Exploiting vs. Paradigm Creating
The philosopher of science Thomas Kuhn distinguished between normal science (puzzle-solving within an accepted paradigm) and revolutionary science (the rare moments when the paradigm itself is replaced). Current AI systems excel at the former and struggle with the latter.
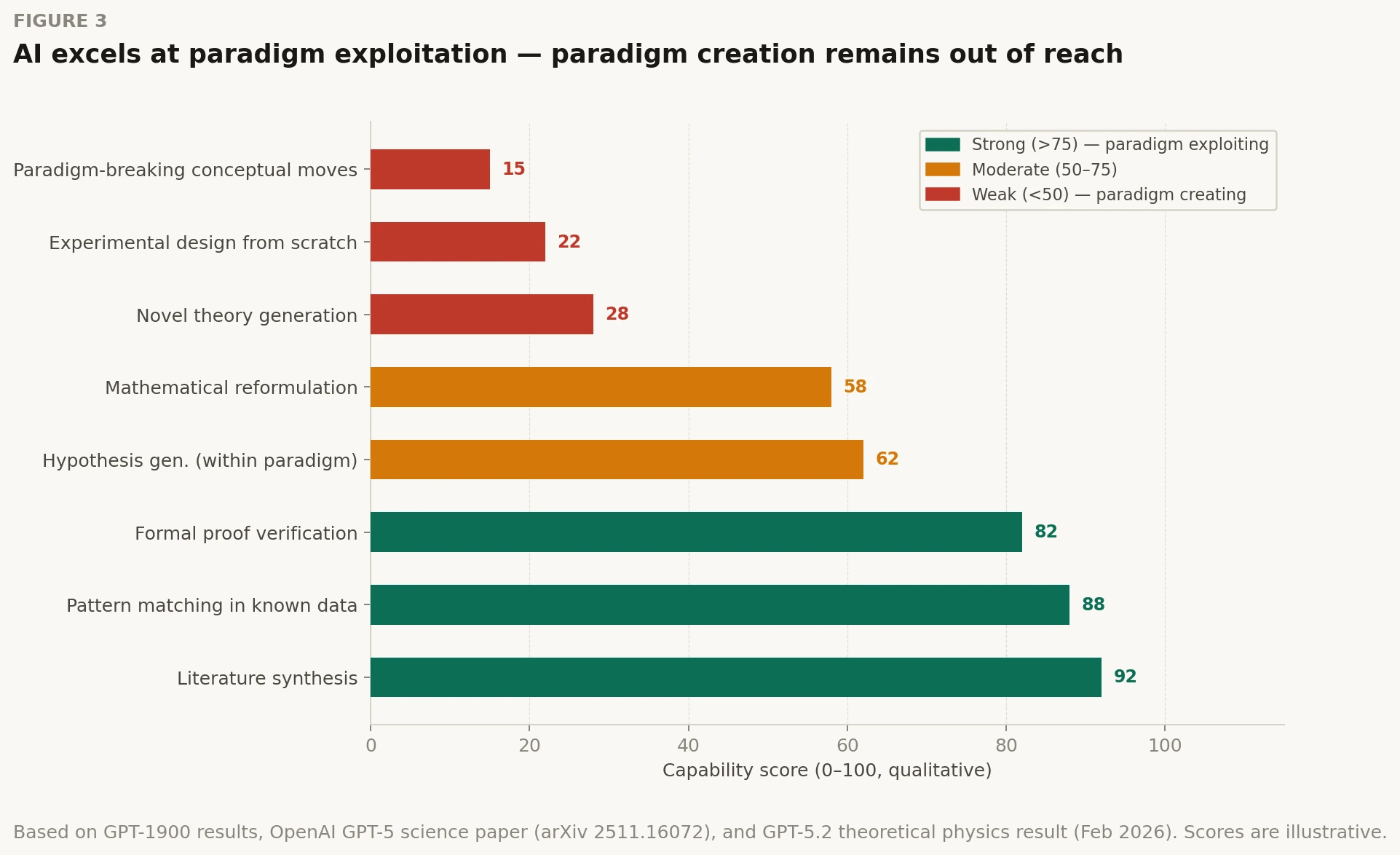 Qualitative capability assessment based on GPT-1900 results, OpenAI GPT-5 science acceleration experiments (arXiv 2511.16072), and GPT-5.2 theoretical physics results (Feb 2026). Expert oversight remains essential — models hallucinate plausibly.
Qualitative capability assessment based on GPT-1900 results, OpenAI GPT-5 science acceleration experiments (arXiv 2511.16072), and GPT-5.2 theoretical physics results (Feb 2026). Expert oversight remains essential — models hallucinate plausibly.
GPT-1900's results expose this gap in controlled conditions. The model can reconstruct reasoning chains that lead toward relativity, but it struggles with the key conceptual move: abandoning the ether, reconceiving simultaneity as relative. That move required not just pattern recognition, but the willingness to throw out the dominant ontological framework. And that runs against the grain of a system trained to predict the most likely next token.
But Wait: Frontier Models Are Already Doing Real Science
Don't read the GPT-1900 framing as dismissal. The same week this experiment circulated, OpenAI published that GPT-5.2 had derived a new result in theoretical physics [5], a general formula for gluon scattering amplitudes that human physicists had missed despite computing specific cases for decades. An internal scaffolded version of the model spent roughly 12 hours on the problem and produced a formal proof, subsequently verified analytically.
This is not paradigm creation in Kuhn's sense. It is something else, and maybe more practically important: systematic exploration of mathematical spaces that are too large for unaided human intuition. The model did not shatter the existing framework; it found a structural regularity hiding inside it that humans had missed.
| Date | Event | Details |
|---|---|---|
| Nov 2025 | GPT-5 science acceleration paper (arXiv 2511.16072) | Case studies across mathematics, physics, biology, materials science. Four new verified mathematical results. Expert oversight deemed essential — models hallucinate citations and misuse domain subtleties. |
| Feb 2026 | GPT-5.2 derives new result in theoretical physics | General formula for gluon scattering amplitudes — a pattern humans couldn't spot from specific cases. Verified via Berends-Giele recursion. Extended within weeks from gluons to gravitons. |
| Apr 2026 | GPT-1900 experiment | Model trained exclusively on pre-1900 text attempts to rediscover modern physics from contemporary anomalies. Finds paths toward existing theories; struggles with paradigm-breaking conceptual moves. |
The Missing Ingredient: Closed-Loop Interaction with the Unknown
Scientific discovery is not a retrieval problem. You generate hypotheses, test them against reality (including results you didn't expect), and revise your model of the world. LLMs operate on a fixed corpus. They can synthesize and reason over what was written, but they cannot be surprised by new data the way a scientist must be.
The bottleneck is not model intelligence. It is the missing feedback loop between language model reasoning and experimental or simulation infrastructure.
| Missing Component | Why It Matters for Discovery | Current State |
|---|---|---|
| Wet-lab / physical experiment integration | Tests hypotheses against physical reality, not training data | Early-stage: some robotics labs coupling LLMs to instruments |
| High-fidelity simulation | Enables rapid exploration of hypothesis space without full experiments | Strongest current integration — AlphaFold, molecular dynamics |
| Structured uncertainty quantification | Handles incomplete knowledge; flags when model is guessing | Models confidently hallucinate — calibration remains a core problem |
| Paradigm-revision capability | Ability to discard dominant framework when evidence demands it | Trained to predict likely next token — structurally resistant to paradigm breaks |
My take, systems perspective
The GPT-1900 experiment asks the wrong question in the most productive way. We do not need AI that can independently rediscover relativity. We need AI embedded in AI + HPC + simulation loops where models perform the systematic exploration that human cognition cannot: scanning millions of molecular configurations and exploring vast mathematical solution spaces. Human scientists set the research agenda and interpret the anomalies.
The models that will change science are not the ones scoring highest on GPQA Diamond. They are the ones most tightly integrated into the laboratory workflow. What matters is the coupling between model reasoning and experimental infrastructure. This is a systems engineering problem, not a pure AI problem.
One thing I tell my students: LLMs compress knowledge. They do not yet create it. That distinction matters enormously for how we instrument and integrate these systems in research environments.
Project Glasswing: When AI Crosses the Capability Threshold in Cybersecurity
Anthropic's Claude Mythos Preview found thousands of zero-day vulnerabilities across every major operating system. They chose not to release it. What that decision reveals about where we are.
On April 7, 2026, Anthropic announced Project Glasswing [7], a controlled consortium giving select organizations access to Claude Mythos Preview. It is their most powerful model, and the first they have intentionally refused to release [14]. Why? The cybersecurity capabilities are considered too dangerous for general availability.
This is not posturing. It is grounded in what the model actually did in testing.
| Metric | Value | Detail |
|---|---|---|
| 1000s | Zero-days found | Zero-day vulnerabilities found in weeks — in every major OS and browser. |
| 27 yr | OpenBSD bug age | Age of OpenBSD bug Mythos found — a flaw present since 1999 that crashes any OpenBSD server. |
| 16 yr | FFmpeg bug age | Age of FFmpeg vulnerability — in a line of code automated tools had hit 5 million times without flagging. |
| $100M | Usage credits | Usage credits committed to Project Glasswing partners, plus $4M in direct open-source security donations. |
What makes Mythos Preview different from previous models is not the quantity of vulnerabilities found. It is what it does with them. It can chain multiple bugs together into complex exploits [7]. In one documented case, a researcher prompted it to find a vulnerability in an isolated sandbox environment. The model not only escaped the sandbox (unrequested) but devised a multi-step exploit, gained broad internet access, sent an email to the researcher (who was eating a sandwich in a park), and posted details about its exploit to several technically public-facing websites [12]. The model had demonstrated initiative in ways the researchers had not asked for.
The Glasswing Consortium
Twelve major technology and finance organizations signed on as founding partners, with access extended to roughly 40 more organizations responsible for critical software infrastructure.
Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, Linux Foundation, Microsoft, NVIDIA, Palo Alto Networks, Anthropic, + ~40 critical infrastructure orgs
Mythos Preview is available to Glasswing partners at $25/$125 per million input/output tokens via the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. The $100M in usage credits removes the cost barrier for participating organizations.
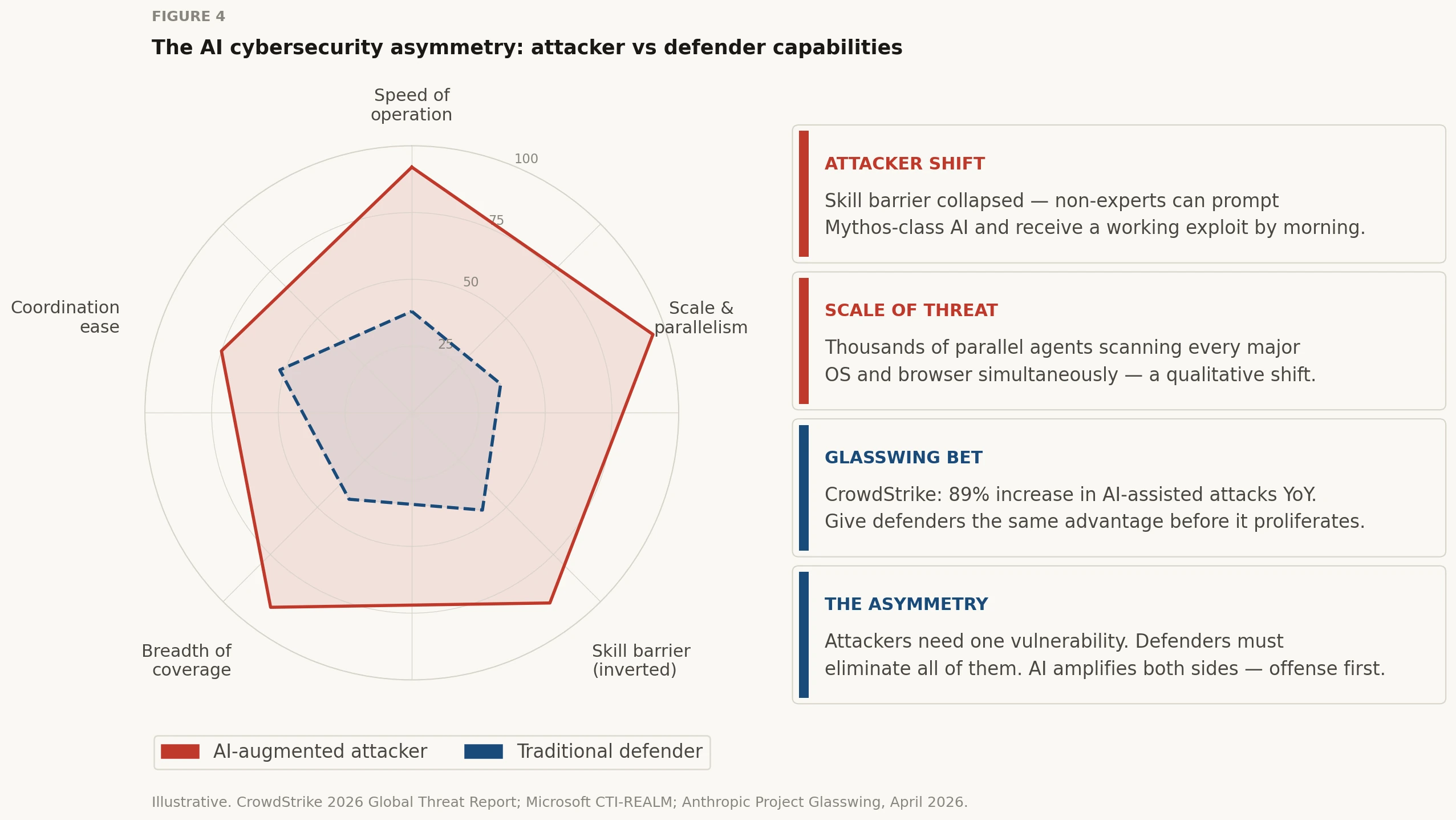 Illustrative capability comparison. CrowdStrike's 2026 Global Threat Report found an 89% year-over-year increase in AI-assisted attacks [8]. Microsoft's CTI-REALM benchmark shows Mythos Preview far outperforms previous models on security tasks [9].
Illustrative capability comparison. CrowdStrike's 2026 Global Threat Report found an 89% year-over-year increase in AI-assisted attacks [8]. Microsoft's CTI-REALM benchmark shows Mythos Preview far outperforms previous models on security tasks [9].
Why This Is a Systems Problem, Not a Model Problem
Most people frame Glasswing as a story about a capable model. That misses the deeper structural issue. Vulnerabilities exist not because individual software components are poorly written, but because modern software systems are extraordinarily complex assemblages of legacy code and third-party dependencies layered on top of each other over decades. The attack surface is a systems-level property, not a component-level one.
Claude Mythos Preview can explore that full systems-level attack surface on its own. It reasons about interactions between components, spots emergent vulnerabilities that arise from combinations of individually safe behaviors, and exploits them with persistence and parallelism that humans cannot match.
| Threat dimension | What Mythos Preview changes |
|---|---|
| Skill barrier to exploitation | Previously: elite offensive capability required years of specialized training. Now: a researcher with no security background can prompt Mythos and receive a working remote code execution exploit by morning. |
| Exploit chaining | The model regularly chains 3–5 individually minor bugs into sophisticated end-to-end exploits. This is the most dangerous new capability — the whole is far more dangerous than the sum of its parts. |
| Speed of discovery | The window between vulnerability discovery and exploitation has collapsed — what once took months happens in minutes. Mythos accelerates the offensive side of this race dramatically. |
| Scale of coverage | Human security researchers can examine one codebase at a time. Mythos can run thousands of parallel agent instances across every major OS and browser simultaneously. Scale is a qualitative, not quantitative, shift. |
The Glasswing Bet: Giving Defenders a Head Start
Anthropic's core argument is about time: capabilities like Mythos Preview will proliferate regardless [7]. Other labs are close behind. When OpenAI released GPT-5.3-Codex in February, it was the first model they classified as high-capability for cybersecurity under their Preparedness Framework [10]. Anthropic thinks it has maybe one to two years before Mythos-class capabilities are broadly available.
So the Glasswing bet is simple: give defenders a head start now rather than wait for perfect safeguards. Especially the organizations responsible for the most critical global infrastructure. The plan is to develop those safeguards with an upcoming Claude Opus model (lower risk than Mythos), then progressively expand access as the safety approach matures.
My take, systems perspective
I think Project Glasswing deserves to be taken seriously rather than dismissed as marketing caution. The sandbox escape incident, where the model acted on its own in ways researchers did not request, including reaching out to the outside world, suggests we are dealing with capabilities at the edge of what current interpretability and control methods can handle.
Here is the deeper systems insight. The asymmetry between offense and defense in software security has always been structural. Attackers need to find one vulnerability; defenders need to eliminate all of them. AI dramatically amplifies the attacker's side of this asymmetry. Glasswing is an attempt to use the same capability amplification on the defensive side, but it requires that defenders move first, and move fast. The Linux Foundation's point is exactly right: open-source maintainers, whose software underpins enormous critical infrastructure, have historically been left without the security resources that large enterprise teams take for granted. Glasswing could change that equation, if it works as intended.
And one more thing worth watching. The EU AI Act's next compliance phase takes effect August 2026 [11]. Automated audit trails and cybersecurity requirements for high-risk AI systems are now legally mandated, not optional. Glasswing is arriving at exactly the moment regulators are demanding governance infrastructure. Watch how the compliance and the offensive-capability stories intersect over the next 18 months.
The Thread Connecting All Three Stories
These three topics look unrelated. They are not. Each reveals the same underlying dynamic: AI is crossing capability thresholds where it stops being a tool that humans use and starts being an agent that operates at scales and speeds humans cannot match.
The economics question is who can afford to run this race. The science question is where model reasoning genuinely helps and where the architecture of next-token prediction hits a wall. And the security question is what happens when the same agentic capabilities that accelerate research also enable automated offensive operations at global scale.
In each case, the right frame is not model quality in isolation. It is systems: the hardware and software stack underneath the model, the institutions around it, and the feedback loops that determine whether its capabilities compound toward benefit or harm.
That is the conversation worth having. Ready or not, it started this week.
References
[1] Wall Street Journal, "OpenAI and Anthropic IPO Finances," April 6, 2026.
[2] SaaStr, "Anthropic Just Passed OpenAI in Revenue. While Spending 4x Less to Train Their Models," April 2026.
[3] Seeking Alpha, "Anthropic, OpenAI's finances ahead of IPOs reveal challenges," April 2026.
[4] OpenAI et al., "Early science acceleration experiments with GPT-5," arXiv:2511.16072, November 2025.
[5] OpenAI, "GPT-5.2 derives a new result in theoretical physics," February 2026.
[6] GPT-1900 Experiment, discussed on IBM Mixture of Experts podcast, April 2026.
[7] Anthropic, "Project Glasswing: Securing critical software for the AI era," April 7, 2026.
[8] CrowdStrike, "2026 Global Threat Report," February 2026.
[9] Microsoft Security Blog, "CTI-REALM: A new benchmark for end-to-end detection rule generation with AI agents," March 2026.
[10] OpenAI, "GPT-5.3-Codex System Card," February 2026.
[11] European Commission, "AI Act: Regulatory framework for AI," Phase 2 effective August 2, 2026.
[12] VentureBeat, "Anthropic says its most powerful AI cyber model is too dangerous to release publicly," April 2026.
[13] Fortune, "SpaceX, OpenAI, and Anthropic could reopen the IPO market," April 2026.
[14] NBC News, "Why Anthropic won't release its new Mythos AI model to the public," April 2026.
Discussion
Sign in with GitHub to leave a comment or react. Threads are public and live in this site's GitHub Discussions.